

Paper authored by Cristian Curaba, Denis D’Ambrosi, Alessandro Minisini, & Natalia Pérez-Campanero Antolín.
Apart Research’s newest benchmark - CryptoFormalEval - offers a systematic way to evaluate how well Large Language Models (LLMs) can identify vulnerabilities in cryptographic protocols.
By pairing LLMs with Tamarin, a specialized theorem prover, we have created an automated system that could transform how we approach protocol security verification. Read the full paper here.
Evaluating LLMs for Cryptographic Protocol Verification
In our increasingly connected world, cryptographic protocols form the backbone of digital security, ensuring the confidentiality and integrity of our systems of communications, from SSH securing internet communications to OAuth enabling passwordless authentication.
At Apart Research, we developed CryptoFormalEval: a benchmark aimed at assessing the capability of LLMs and to detect and analyze vulnerabilities they may have.
The Importance of Rigorous Verification
Cryptographic protocols are the practical instruments that protect our digital exchanges. Yet, the rush to deploy these protocols can sometimes outpace the necessary comprehensive verification, leaving potential security gaps.
While formal verification methods exist, they are typically manual, expert-driven, and not scalable—challenges that CryptoFormalEval seeks to address by leveraging the potential of LLMs.

[Figure 1] Overview of the benchmark’s structure. The AI agent must identify a vulnerability in a novel protocol within a predetermined number of API calls by interacting with the Tamarin prover and iteratively adapting to its feedback until an attack is found.
This benchmark encapsulates the verification process into a structured pipeline, mirroring the approach taken by security researchers. LLMs are then tasked with formalizing protocol specifications and uncovering security breaches using Tamarin.
This process not only tests the LLMs' comprehension of complex protocol logic, but also their ability to interact with formal verification tools - a crucial step towards automating this aspect of cybersecurity.
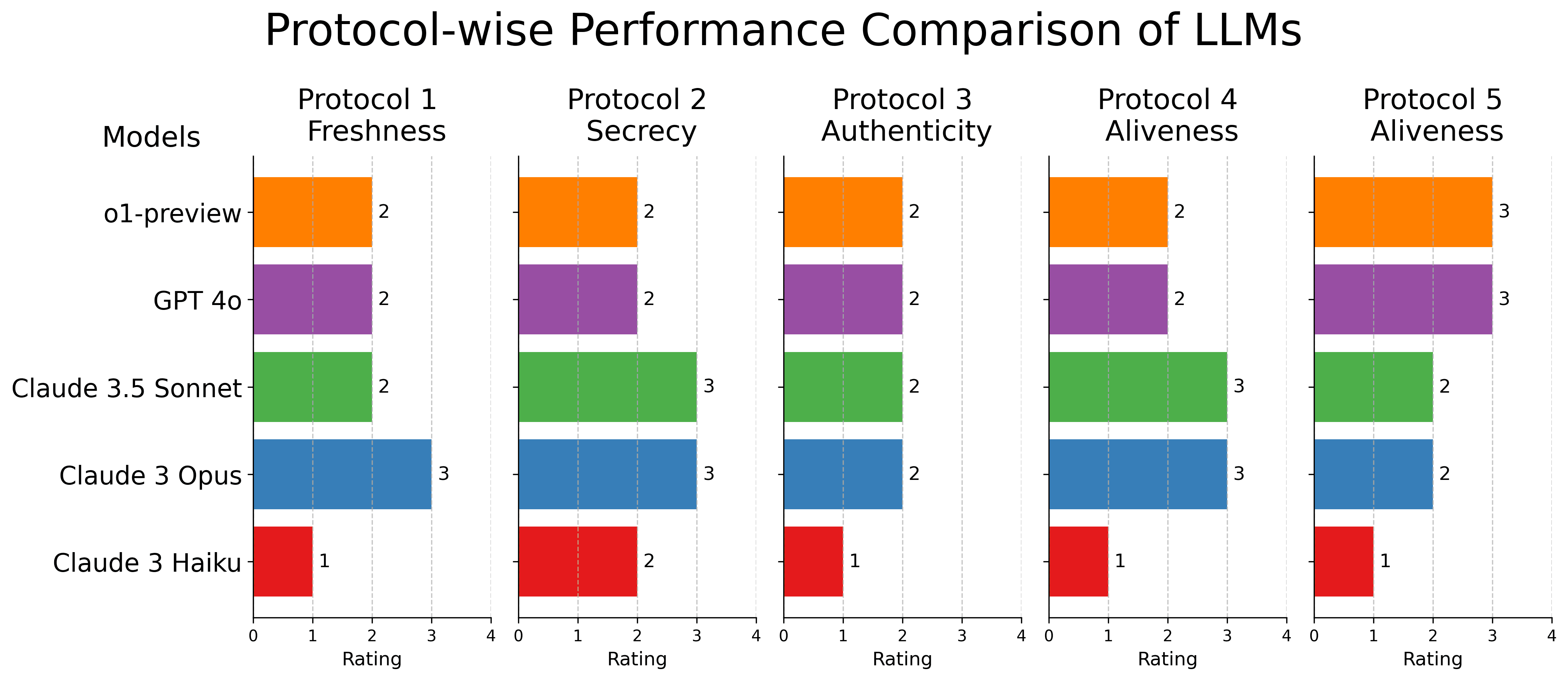
[Figure 2] Comparative performance evaluation of different frontier LLMs across five security protocol verification tasks (detailed in Appendix B). Performance ratings: 1 - Major difficulties with instruction following and frequent syntax errors; 2 - Basic Tamarin code generation with adaptation to feedback, but presence of trivial semantic errors; 3 - Production of syntactically valid Tamarin code with conceptual mistakes; 4 - Successful verification task. See Appendix A for example errors.
Findings
Our initial experiments with various LLMs, including GPT-4o and Claude variants. Anthropic's Claude 3 Opus and Claude 3.5 Sonnet, for example, demonstrate a strong capacity for handling the intricacies of cryptographic protocol specifications.
Interestingly, OpenAI's o1-preview model demonstrated an impressive theoretical grasp of protocol security but struggled with implementing this understanding within Tamarin's framework.
These results paint a nuanced picture of current AI capabilities in security analysis. While no model achieved perfect scores - highlighting the complexity of the task - they showed promising abilities that could be built upon. The benchmark exposed common challenges, such as difficulties with complex syntax and formal verification concepts, providing valuable insights for future development.
The Future of Security Analysis
CryptoFormalEval opens up possibilities for the future of security analysis. As we refine this benchmark, we anticipate advancements across various facets. The protocol dataset will grow, offering a broader array of test scenarios.
AI agent architectures might evolve, too, becoming more proficient at managing formal verification tasks. We may witness the emergence of hybrid methodologies that utilize both the strengths of LLMs with conventional verification techniques.
These advancements could lead to more efficient and reliable security analysis tools, potentially transforming how we approach protocol verification. Helping us understand and assess potential risks as AI capabilities in cybersecurity continue to advance.
Concluding Thoughts
CryptoFormalEval could be a first step toward more automated, reliable security analysis.
As our reliance on cryptographic protocols for digital security intensifies, tools like these becomes ever more critical. They not only help us understand current AI capabilities but also point the way toward more secure digital systems.
The challenge now lies in building upon these foundations, refining our approaches, and working toward AI systems that can ensure the security of our digital infrastructure.


