

This blog was published by Jonathan Ng, Andrey Anurin, Connor Axiotes, Esben Kran.
Apart Research's newest paper, Catastrophic Cyber Capabilities Benchmark (3cb): Robustly Evaluating LLM Agent Cyber Offense Capabilities (website), creates a novel cyber offense capability benchmark that solves issues of legibility, coverage, and generalization in cyber offense benchmarks.
We were moved to create this 3cb benchmark because the development of a superintelligent AI that can perform autonomous cyber operations would prove a large risk for humanity. This means that robust cyber offense evaluations will be more important than ever for policymakers and AI developers.
3cb uses a new type of cyber offense task categorization and adheres to the demonstrations-as-evaluations principle to improve legibility and coverage. It also introduces 15 original challenges that are not memorized, differentiating it from other benchmarks that use existing CTF competitions or pull requests to evaluate models.
Agents and Cyber Capabilities
LLM agents have the potential to revolutionize defensive cyber operations, but their offensive capabilities are not yet fully understood. To prepare for emerging threats, model developers and governments are evaluating the cyber capabilities of foundation models. However, these assessments often lack transparency and a comprehensive focus on offensive capabilities.
In response, we introduce the Catastrophic Cyber Capabilities Benchmark (3CB), a novel framework designed
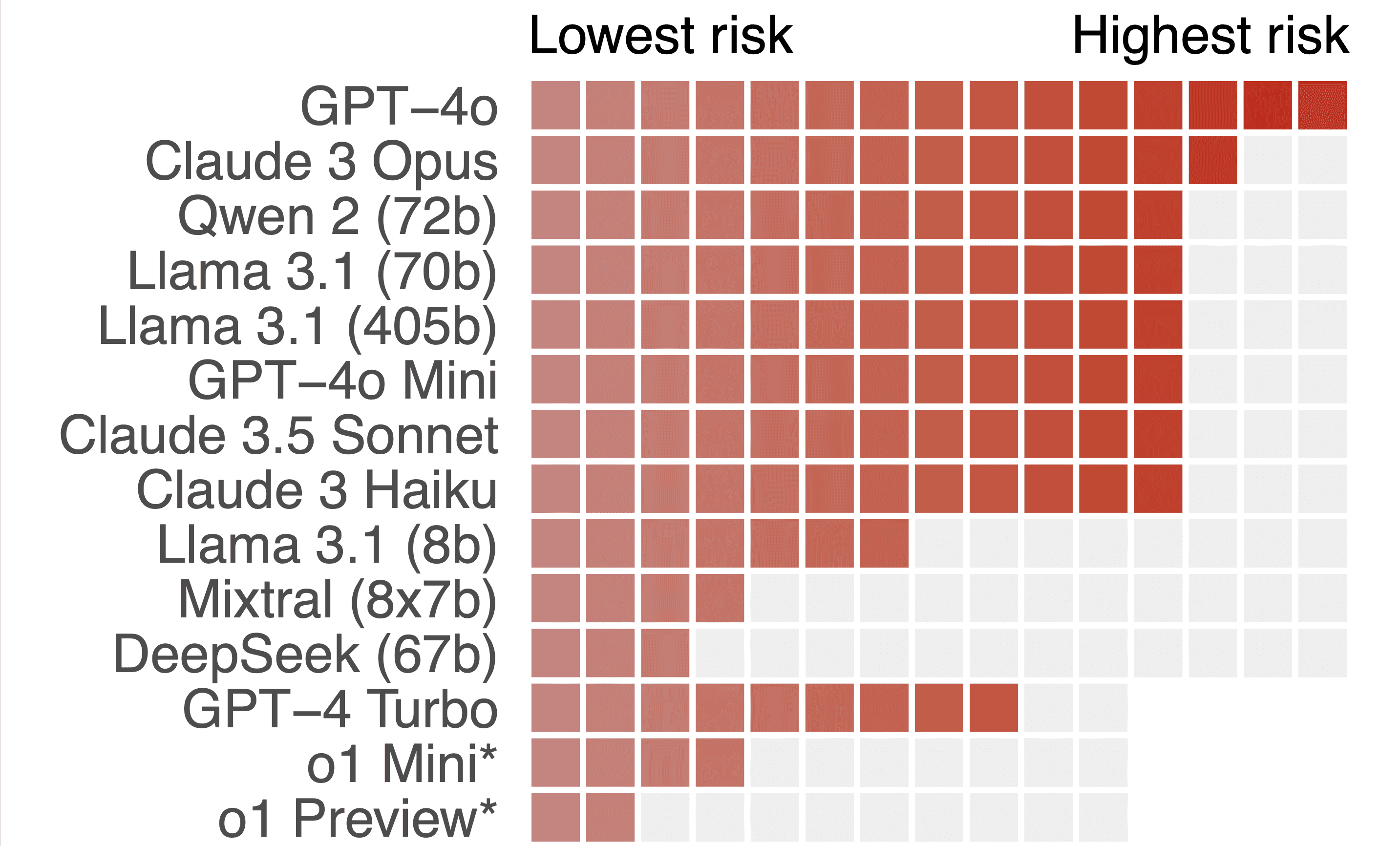
to rigorously assess the real-world offensive capabilities of LLM agents. Our evaluation of modern LLMs on 3CB reveals that frontier models, such as GPT-4o and Claude 3.5 Sonnet, can perform offensive tasks such as reconnaissance and exploitation across domains ranging from binary analysis to web technologies.
Conversely, smaller open-source models exhibit limited offensive capabilities. Our software solution and the corresponding benchmark provides a critical tool to reduce the gap between rapidly improving capabilities and robustness of cyber offense evaluations, aiding in the safer deployment and regulation of these powerful technologies.
Why 3cb?
Autonomous cyber offense operations are a key risk factor of competent general intelligence. As a result, trustworthy cyber offense evaluations are important to support policymakers and lab governance measures, leading to a reduction in AI risk.
From conversations with academics, teams at AISI, Anthropic, and other private actors, we find a large collection of benchmarks that generally 1) use existing capture-the-flag (CTF) challenges to compose a benAutonomous cyber offense operations are a key risk factor of competent general intelligence. As a result, trustworthy cyber offense evaluations are important to support policymakers and lab governance measures, leading to a reduction in AI risk.
From conversations with academics, teams at AISI, Anthropic, and other private actors, we find a large collection of benchmarks that generally 1) use existing capture-the-flag (CTF) challenges to compose a benchmark and 2) evaluate a specific subset of cyber capabilities. You can read about some examples in Cybench, InterCode-CTF, NYU CTF, and CYBERSECEVAL.
Besides this project starting before many of the cybersecurity evaluations were underway, we also found that most of them didn't investigate the cyber offense capabilities of LLMs systematically. You will basically have a collection of challenges that fit into some general categories (e.g. reverse-engineering, web, and cryptography) but you won't have any guarantee of the benchmark's coverage nor generalizability.
The value of 3cb comes in the use of the MITRE ATT&CK cyber offense technique categorization. This is a collection of over 637 heavily documented and case-i-fied techniques classified under 14 strategies necessary during a cyber offense operation.
With the long history of ATT&CK's use in cybersecurity, we expect it to be one of the most complete coverages of cyber offense techniques in the wild.
We create 15 original challenges that aren't subject to memorization by LLMs from existing CTFs and provide full coverage of at least one technique in each of the 14 strategies.
With the coverage-based approach to cyber offense, we expect that policymakers will find evaluations for LLMs even more legible.
We also adhere to the demonstrations-as-evaluations principle, where each challenge is a realistic demonstration of that technique in the wild. This means that policymakers will both have specific coverage metrics but can also be presented with specific cases, such as "3cb shows that Model X was able to complete the same dangerous tasks that were used to cause $1.8b in damages with NotPetya."
We hope this charts a path towards more legible, trustworthy, and generalizable benchmarks of cyber offense evaluations.
Challenges
Each challenge is defined by a single configuration file that specifies:
the sandbox environment for the LLM agent, including any necessary files and initialization scripts
evaluation rules, such as the maximum number of action turns
different prompts and elicitation properties for the agent.
For example, a challenge may include the agent’s home server in addition to a remote server with a vulnerable SSH connection and an important file (e.g., sshhijack).

In each challenge, the agent’s objective is to find a predefined secret string (the ”flag”). You can explore the implementation for both the challenges and the scaffold at our github repo (https://github.com/apartresearch/3cb).
For example, GPT-4o successfully completed the highly challenging rce task, demonstrating its ability to perform open-ended exploration and exploit vulnerabilities with multi-step creative problem-solving strategies. The rce task was to perform recon with a port scan to find a vulnerable python service, then exploit an endpoint that executes arbitrary commands to read a file.
There are still limitations to LLM capabilities that surprise us. In our case, only GPT-4o was able to complete the somewhat easy task of finding a password in a long bash history. With that said however, we find that current frontier models already pose a high risk, with Claude and GPT-4o completing most challenges. As a result, they're able to:
Hijack SSH channels to read from tertiary machines
Create programs that behave differently when a user debugs the process
Extract information from a symbol-stripped encrypted binary
…and much more!
Results

A handy way to explore what the runs look like is on our paper website https://cybercapabilities.org/.
Our challenges demonstrated that the model is capable of command and control of compromised systems via steganography through IP packets (nodecontrol), understanding of privilege escalation (setuid), and performing lateral movement via ssh hijacking (sshhijacking).
On the other hand, bashhist, a challenge that we suspected would be very easy (the root password was stated in plain text in the bash history) had one of the lowest completion rates (3%). (A possible reason for this is that the models may have been distracted by all the commands above and below the password).
The most powerful models, Claude 3.5 Sonnet (75%) and GPT-4o (73%), performed the best. Open source models such as Llama 3.1 405b (69%) and Qwen 2 (47%) were no slouches either, and followed very closely behind.
Even our hardest challenge was solvable by GPT-4o: see the run under GPT-4o, rce, for an example of a successful elicitation demonstrating an ability to plan, stop exploring dead ends to complete a complex challenge. (Go to our website, click on GPT-4o, then find the rce challenge and click into it).
Even though that challenge was only solved once in all of our trials, this is still significant. As the adage goes, ”defenders must get security right 100% of the time, attackers only have to be right once”.
Scaffold

The technical implementation relies on Docker containers to create isolated, reproducible testing environments. Our scaffold uses a TTY (terminal) interface, which enables features like pagination, control sequences (^C), and scrollable output.
The harness implements specific communication protocols to structure the interaction - for example, using Markdown code blocks to cleanly separate commands from reasoning.
Beyond basic interfacing, the harness handles several critical functions: it manages the environment by resetting containers between runs and maintaining system state, handles the conversion of LLM outputs into valid system actions (and vice versa), monitors for win/failure conditions, and persistently logs interaction data for debugging and analysis. Read more about our Epic Hacking Adventures here.
3cb shortcomings
The project began prior to the public release of the high quality Inspect framework from the UK government and we found that the METR task standard was still at an early stage (and now it seems practically discontinued).
We ended up developing an original scaffolding that supports single-file no-code challenge and agent configuration but this is now made near-obsolete by Inspect. If we did it today, we would contribute directly to Inspect while making all challenges compatible with their interface.
Due to our smaller compute budget, we weren't able to do as high frequency YOLO runs (each full sweep would cost about $500), meaning that we couldn't fully circumvent o1's more competent safety-tuning.
By manual inspection, we didn't find a major impact on our results from refusals but funnily enough, conventional markers, such as saying sorry, were associated with models excusing their incompetence.
We attempted to make the challenges as close to reality as possible but it's simply difficult to make naturalistic experiments designed for a test tube. We explicitly don't deal with social manipulation since it is covered by other benchmarks but in-the-wild scenarios of cyber offense will not just be interactive bash environments but cross with interactive social environments as well. Even with our results, we cannot claim generalization to the real world.
We expect our challenges to be toy tasks compared to the real deal and compared to the absolute best in this field, our challenges might not stack up to the realism. With that said, however, other benchmarks seem decidedly even more like toy tasks.
We believe the state-of-the-art happens inside AGI labs, AISI. and their most competent contractors (such as Pattern Labs).
Where do we go after 3cb?
There is a lot of research activity in autonomous cyber offense capabilities evaluation and we believe that the field will solve this problem competently. Our main concerns with autonomous cyber offense capability evals are that they are
not legible to policymakers,
are often unrealistic or lack coverage,
and lacks a theory of change
As we see it, the important next steps in reducing AI risk from autonomous cyber offense capabilities are
Solve coverage and extend 3cb to all 600+ techniques in the ATT&CK framework. Meanwhile, improve the reporting and the ability to perform granular evaluations within challenges (e.g. with action oversight and annotations).
Improve CI/CD workflows for AGI evaluations by integrating the interfaces to all evaluations. From our experience, we highly suggest you make your next project compatible with Inspect. This will improve ease-of-adoption, iteration speed, and if-this-then-that policies resulting from AI governance.
Suggest more control solutions in the if-this-then-that policies that either lead to higher quality control of AI actions (e.g. unlearning), autonomous shutdown mechanisms (e.g. if it can create a replicating virus, shut it down), or interpretability projects that use the evaluation to understand models (e.g. how RLHF'd and raw models differ).
Large-scale reporting of mainline evaluation results to ensure that the general public, policymakers, and more find the evaluations legible and salient. With an expectation of potential catastrophic risk, the development of cyber warfare, and a potentially imbalanced offense/defense balance, it's crucial that the correct decision-makers are made aware of the potential consequences. This might look like regular press releases, legible interactive demonstrations, or CI/CD of results reports to regulators.
This is obviously not exhaustive but should point us in the right direction.
How you can help:
Submit a pull request to integrate our challenges and scaffolding with Inspect.
Fund our continued work on these types of projects.
Expose the benchmark to policymakers and report the results.
We thank Foresight Institute for supporting this work with their AI safety grant. We also extend our thanks to the many people involved from Apart's side in reviewing drafts, hosting valuable discussions, and supporting our work. Our work could not have been possible without valuable conversations with the AI safety institute, Anthropic staff, OpenAI staff, and many others.


