-
Online & In-Person
Global South AI Safety Hackathon

AI safety research is concentrated in a handful of countries. This hackathon changes that. Build AI safety tools, evaluations, and policy research from Latin America, Africa, or Asia, compete within your region, and join a pipeline from hackathon to fellowship to placement. With Support from Schmidt Sciences.
00:00:00:00
Days To Go
AI safety research is concentrated in a handful of countries. This hackathon changes that. Build AI safety tools, evaluations, and policy research from Latin America, Africa, or Asia, compete within your region, and join a pipeline from hackathon to fellowship to placement. With Support from Schmidt Sciences.
This event is ongoing.
This event has concluded.
Sign Ups
Entries
Overview
Resources
Guidelines
Schedule
Entries
Overview

HACKATHON WINNERS
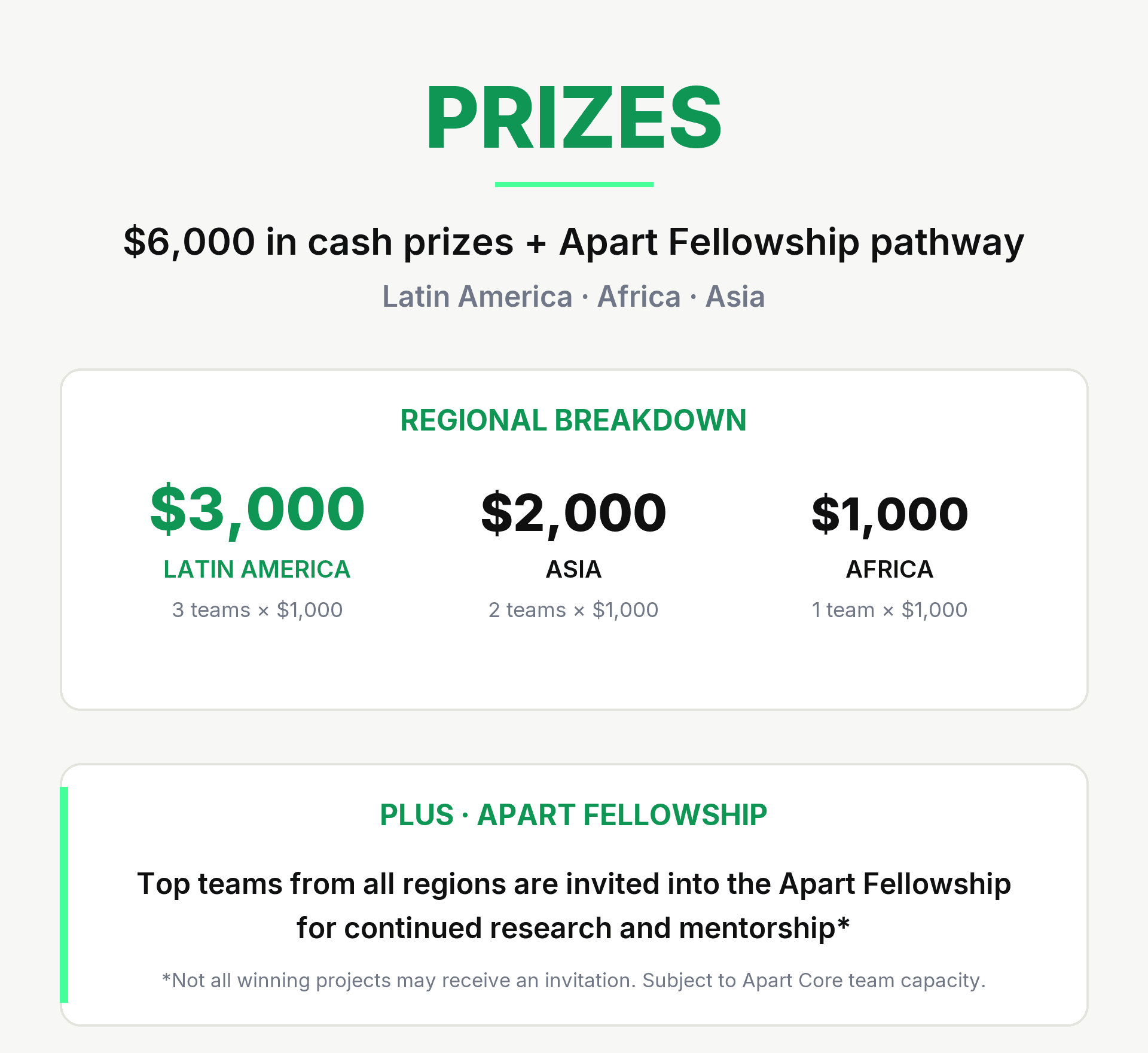
Congratulations to our winning teams, and thank you to everyone who submitted. We received 217 projects across three tracks, from hubs and participants across Latin America, Africa, and Asia, with support from Schmidt Sciences. The bar was high throughout. Each regional winner receives $1,000.
🌎 Latin America
🥇 Coldron by Leonardo Párraga, Angie Giraldo & Víctor Gelves
🥇 Probing Latent Colombian Identity Inferences in Qwen2.5-7B with Natural Language Autoencoders by UAO SAFETY
🥇 Thought Anchors for Social Bias: Which Reasoning Steps Matter in Extended Thinking LLMs on Latin American Scenarios by Andres Felipe Mosquera Hernandez
🌏 Asia-Pacific
🥇 STEER: Mech interp-based white box attack on LLMs by Joshua Adrian Cahyono
🥇 Do Multilingual Vision-Language Models Abstain under Cross-Modal Conflict in Low-Resource Languages? by Anvesh Reddy Lankala, Vicky Feliren & Akansh Jain
🌍 Africa
🥇 Confidently Wrong: Measuring and Mitigating Calibration Risks in LLMs for African Languages by Team AIMS South Africa
🎖️ Honorable Mentions
Non-cash recognition for standout work, with these teams under consideration for the Apart Fellowship.
JusticIA
Pragmatic Sophistry in Vietnamese Multi-Agent Oversight
¿Por qué los agentes obedecen?
Local-Geometry Signals of Capability Emergence During Portuguese Grammar Acquisition
IndicViet-Safe
The Shapes of Bias in Spanish-Prompted LLMs and the Debiasing Prompt Scaffolds
Ufakazi
—————————————————————————————————————————————————
The Global South AI Safety Hackathon brings together researchers, engineers, and policy professionals across Latin America, Africa, and Asia to work on AI safety problems that matter most in their regions. Over one weekend, participants build tools, evaluations, and policy research addressing gaps the field has overlooked.
The hackathon is designed for and with the Global South. Participants compete within their region, not globally. The best teams from all regions are invited into the Apart Fellowship for continued research and mentorship.
Why the Global South?
AI safety research is concentrated in a handful of countries. None of the top 100 institutions by AI publication index, in either universities or companies, are based in Africa or Latin America (Chan et al., 2021). Meanwhile, AI risks hit differently in these regions: jailbreaks are more common in low-resource languages, and algorithmic bias trained on non-local data shows up in healthcare and hiring deployments.
This hackathon is not about bringing AI safety to the Global South. It is about bringing the Global South into AI safety. Researchers here have contextual knowledge the field needs: regulatory landscapes, language gaps, and institutional constraints that determine whether safety research actually works in practice.
Regional Tracks
Participants compete within their region. Each region has its own winners and prizes. Within each regional track, participants choose a sub-track (Technical AI Safety, AI Governance/Policy, or a locally-tailored sub-track defined by their hub). If you're based outside the three regions, you can still take part through the Open Track below.
Track 1: Latin America
Hubs in São Paulo, Buenos Aires, Bogotá, México: Merida-Guadalajara. Three winning teams ($3,000 total).
Brazil's AI bill (PL 2.338/2023), approved by the Senate and pending Chamber vote, includes a standalone human rights chapter that goes beyond the EU AI Act. Chile became the first country in the world to constitutionally protect neuro-rights. Colombia's CONPES 4144 established a national AI policy framework in early 2025.
We encourage submissions in three sub-tracks:
Technical safety: AI fairness for Portuguese and Spanish language models, safety evaluations for AI systems deployed in Latin American contexts.
Governance: regulatory analysis of emerging legislation across the region.
Locally-tailored: problems defined by your hub that reflect local context.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 2: Africa
Hub in Cape Town. One winning team ($1,000 total).
Africa faces risks from advanced AI that are not addressed through frontier AI safety efforts. African-context deployment-side risks include deepfake-driven electoral interference, data-colonial dependency on foreign infrastructure, compute and semiconductor scarcity constraining sovereign AI capacity, and large-scale labour market disruptions. This hackathon is an opportunity to prototype African-context solutions for misuse resilience, differential defence acceleration, and mitigating gradual disempowerment.
We encourage submissions in three sub-tracks:
Policy: recommendations grounded in African regulatory and institutional contexts.
Evals and benchmarks: work that builds on existing efforts and transfers to African contexts.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 3: Asia
Hubs in Bengaluru (Electric Sheep), New Delhi (Secure AI Futures Lab), and Vietnam (Hanoi and Ho Chi Minh City). Two winning teams ($2,000 total).
Asia spans the full spectrum of AI governance approaches. India's "Seven Sutras" framework explicitly prioritizes innovation over restraint. China has enacted more sector-specific AI regulations than any other country. Vietnam's AI law took effect in March 2026, the first binding AI legislation in Southeast Asia. The ASEAN Guide on AI Governance and Ethics offers a voluntary regional framework. Projects can address cross-border governance harmonization, safety evaluations for non-English language models, technical AI safety research, or region-specific risk assessments.
We encourage submissions in three sub-tracks:
Governance and geopolitics: AI compliance, AI sovereignty, national data security, compute diffusion and access.
Socio-economic impacts: deepfakes and misinformation, caste bias, algorithmic bias across ethnic minorities, languages, and dialects, AI misdiagnosis in rural healthcare, gig platforms, labor displacement, gradual disempowerment, and cooperative AI.
Technical safety: cybersecurity, multilingual, multimodal, and open-source models, small AI, and on-device AI.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 4: Open
Based outside Latin America, Africa, and Asia? You can still take part. Submit your project to the Open Track and build the same way the regional tracks do: a tool, evaluation, or policy analysis on any AI safety problem that matters to you.
Who should participate?
Founders and entrepreneurs
AI safety researchers and engineers
Machine learning researchers and engineers
Policy researchers working on AI governance
Software engineers interested in safety infrastructure
Security researchers and red teamers
Students and early-career researchers exploring AI safety
Anyone working on AI and its impacts in the Global South
What you will do
Over three days, you will:
Form teams and choose a regional track and sub-track
Research and scope a specific problem using the provided resources
Build a project: a tool, evaluation, policy analysis, or research contribution
Submit a research report (PDF) documenting your approach, results, and implications
Have your work reviewed by judges from AI safety organizations, universities, and policy institutions in your region
What happens next
After the hackathon, all submitted projects are reviewed by expert judges. Top projects receive prizes. The best teams may be invited into the Apart Fellowship for continued research and mentorship (subject to the asterisked caveat in Overview).
Organized by
Apart Research
Local hubs (8):
Latin America: BAISH (Buenos Aires) | EA Brasil (São Paulo) | AI Safety Colombia (Bogotá) | AISMX (Mérida and Guadalajara)
Africa: AI Safety South Africa (Cape Town)
Asia: Electric Sheep (Bengaluru) | Secure AI Futures Lab (New Delhi) | AnToàn.AI (Hanoi and Ho Chi Minh City)
Supported by Schmidt Sciences.
Sign Ups
Entries
Overview
Resources
Guidelines
Schedule
Entries
Overview
HACKATHON WINNERS
Congratulations to our winning teams, and thank you to everyone who submitted. We received 217 projects across three tracks, from hubs and participants across Latin America, Africa, and Asia, with support from Schmidt Sciences. The bar was high throughout. Each regional winner receives $1,000.
🌎 Latin America
🥇 Coldron by Leonardo Párraga, Angie Giraldo & Víctor Gelves
🥇 Probing Latent Colombian Identity Inferences in Qwen2.5-7B with Natural Language Autoencoders by UAO SAFETY
🥇 Thought Anchors for Social Bias: Which Reasoning Steps Matter in Extended Thinking LLMs on Latin American Scenarios by Andres Felipe Mosquera Hernandez
🌏 Asia-Pacific
🥇 STEER: Mech interp-based white box attack on LLMs by Joshua Adrian Cahyono
🥇 Do Multilingual Vision-Language Models Abstain under Cross-Modal Conflict in Low-Resource Languages? by Anvesh Reddy Lankala, Vicky Feliren & Akansh Jain
🌍 Africa
🥇 Confidently Wrong: Measuring and Mitigating Calibration Risks in LLMs for African Languages by Team AIMS South Africa
🎖️ Honorable Mentions
Non-cash recognition for standout work, with these teams under consideration for the Apart Fellowship.
JusticIA
Pragmatic Sophistry in Vietnamese Multi-Agent Oversight
¿Por qué los agentes obedecen?
Local-Geometry Signals of Capability Emergence During Portuguese Grammar Acquisition
IndicViet-Safe
The Shapes of Bias in Spanish-Prompted LLMs and the Debiasing Prompt Scaffolds
Ufakazi
—————————————————————————————————————————————————
The Global South AI Safety Hackathon brings together researchers, engineers, and policy professionals across Latin America, Africa, and Asia to work on AI safety problems that matter most in their regions. Over one weekend, participants build tools, evaluations, and policy research addressing gaps the field has overlooked.
The hackathon is designed for and with the Global South. Participants compete within their region, not globally. The best teams from all regions are invited into the Apart Fellowship for continued research and mentorship.
Why the Global South?
AI safety research is concentrated in a handful of countries. None of the top 100 institutions by AI publication index, in either universities or companies, are based in Africa or Latin America (Chan et al., 2021). Meanwhile, AI risks hit differently in these regions: jailbreaks are more common in low-resource languages, and algorithmic bias trained on non-local data shows up in healthcare and hiring deployments.
This hackathon is not about bringing AI safety to the Global South. It is about bringing the Global South into AI safety. Researchers here have contextual knowledge the field needs: regulatory landscapes, language gaps, and institutional constraints that determine whether safety research actually works in practice.
Regional Tracks
Participants compete within their region. Each region has its own winners and prizes. Within each regional track, participants choose a sub-track (Technical AI Safety, AI Governance/Policy, or a locally-tailored sub-track defined by their hub). If you're based outside the three regions, you can still take part through the Open Track below.
Track 1: Latin America
Hubs in São Paulo, Buenos Aires, Bogotá, México: Merida-Guadalajara. Three winning teams ($3,000 total).
Brazil's AI bill (PL 2.338/2023), approved by the Senate and pending Chamber vote, includes a standalone human rights chapter that goes beyond the EU AI Act. Chile became the first country in the world to constitutionally protect neuro-rights. Colombia's CONPES 4144 established a national AI policy framework in early 2025.
We encourage submissions in three sub-tracks:
Technical safety: AI fairness for Portuguese and Spanish language models, safety evaluations for AI systems deployed in Latin American contexts.
Governance: regulatory analysis of emerging legislation across the region.
Locally-tailored: problems defined by your hub that reflect local context.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 2: Africa
Hub in Cape Town. One winning team ($1,000 total).
Africa faces risks from advanced AI that are not addressed through frontier AI safety efforts. African-context deployment-side risks include deepfake-driven electoral interference, data-colonial dependency on foreign infrastructure, compute and semiconductor scarcity constraining sovereign AI capacity, and large-scale labour market disruptions. This hackathon is an opportunity to prototype African-context solutions for misuse resilience, differential defence acceleration, and mitigating gradual disempowerment.
We encourage submissions in three sub-tracks:
Policy: recommendations grounded in African regulatory and institutional contexts.
Evals and benchmarks: work that builds on existing efforts and transfers to African contexts.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 3: Asia
Hubs in Bengaluru (Electric Sheep), New Delhi (Secure AI Futures Lab), and Vietnam (Hanoi and Ho Chi Minh City). Two winning teams ($2,000 total).
Asia spans the full spectrum of AI governance approaches. India's "Seven Sutras" framework explicitly prioritizes innovation over restraint. China has enacted more sector-specific AI regulations than any other country. Vietnam's AI law took effect in March 2026, the first binding AI legislation in Southeast Asia. The ASEAN Guide on AI Governance and Ethics offers a voluntary regional framework. Projects can address cross-border governance harmonization, safety evaluations for non-English language models, technical AI safety research, or region-specific risk assessments.
We encourage submissions in three sub-tracks:
Governance and geopolitics: AI compliance, AI sovereignty, national data security, compute diffusion and access.
Socio-economic impacts: deepfakes and misinformation, caste bias, algorithmic bias across ethnic minorities, languages, and dialects, AI misdiagnosis in rural healthcare, gig platforms, labor displacement, gradual disempowerment, and cooperative AI.
Technical safety: cybersecurity, multilingual, multimodal, and open-source models, small AI, and on-device AI.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 4: Open
Based outside Latin America, Africa, and Asia? You can still take part. Submit your project to the Open Track and build the same way the regional tracks do: a tool, evaluation, or policy analysis on any AI safety problem that matters to you.
Who should participate?
Founders and entrepreneurs
AI safety researchers and engineers
Machine learning researchers and engineers
Policy researchers working on AI governance
Software engineers interested in safety infrastructure
Security researchers and red teamers
Students and early-career researchers exploring AI safety
Anyone working on AI and its impacts in the Global South
What you will do
Over three days, you will:
Form teams and choose a regional track and sub-track
Research and scope a specific problem using the provided resources
Build a project: a tool, evaluation, policy analysis, or research contribution
Submit a research report (PDF) documenting your approach, results, and implications
Have your work reviewed by judges from AI safety organizations, universities, and policy institutions in your region
What happens next
After the hackathon, all submitted projects are reviewed by expert judges. Top projects receive prizes. The best teams may be invited into the Apart Fellowship for continued research and mentorship (subject to the asterisked caveat in Overview).
Organized by
Apart Research
Local hubs (8):
Latin America: BAISH (Buenos Aires) | EA Brasil (São Paulo) | AI Safety Colombia (Bogotá) | AISMX (Mérida and Guadalajara)
Africa: AI Safety South Africa (Cape Town)
Asia: Electric Sheep (Bengaluru) | Secure AI Futures Lab (New Delhi) | AnToàn.AI (Hanoi and Ho Chi Minh City)
Supported by Schmidt Sciences.
Sign Ups
Entries
Overview
Resources
Guidelines
Schedule
Entries
Overview

HACKATHON WINNERS
Congratulations to our winning teams, and thank you to everyone who submitted. We received 217 projects across three tracks, from hubs and participants across Latin America, Africa, and Asia, with support from Schmidt Sciences. The bar was high throughout. Each regional winner receives $1,000.
🌎 Latin America
🥇 Coldron by Leonardo Párraga, Angie Giraldo & Víctor Gelves
🥇 Probing Latent Colombian Identity Inferences in Qwen2.5-7B with Natural Language Autoencoders by UAO SAFETY
🥇 Thought Anchors for Social Bias: Which Reasoning Steps Matter in Extended Thinking LLMs on Latin American Scenarios by Andres Felipe Mosquera Hernandez
🌏 Asia-Pacific
🥇 STEER: Mech interp-based white box attack on LLMs by Joshua Adrian Cahyono
🥇 Do Multilingual Vision-Language Models Abstain under Cross-Modal Conflict in Low-Resource Languages? by Anvesh Reddy Lankala, Vicky Feliren & Akansh Jain
🌍 Africa
🥇 Confidently Wrong: Measuring and Mitigating Calibration Risks in LLMs for African Languages by Team AIMS South Africa
🎖️ Honorable Mentions
Non-cash recognition for standout work, with these teams under consideration for the Apart Fellowship.
JusticIA
Pragmatic Sophistry in Vietnamese Multi-Agent Oversight
¿Por qué los agentes obedecen?
Local-Geometry Signals of Capability Emergence During Portuguese Grammar Acquisition
IndicViet-Safe
The Shapes of Bias in Spanish-Prompted LLMs and the Debiasing Prompt Scaffolds
Ufakazi
—————————————————————————————————————————————————
The Global South AI Safety Hackathon brings together researchers, engineers, and policy professionals across Latin America, Africa, and Asia to work on AI safety problems that matter most in their regions. Over one weekend, participants build tools, evaluations, and policy research addressing gaps the field has overlooked.
The hackathon is designed for and with the Global South. Participants compete within their region, not globally. The best teams from all regions are invited into the Apart Fellowship for continued research and mentorship.
Why the Global South?
AI safety research is concentrated in a handful of countries. None of the top 100 institutions by AI publication index, in either universities or companies, are based in Africa or Latin America (Chan et al., 2021). Meanwhile, AI risks hit differently in these regions: jailbreaks are more common in low-resource languages, and algorithmic bias trained on non-local data shows up in healthcare and hiring deployments.
This hackathon is not about bringing AI safety to the Global South. It is about bringing the Global South into AI safety. Researchers here have contextual knowledge the field needs: regulatory landscapes, language gaps, and institutional constraints that determine whether safety research actually works in practice.
Regional Tracks
Participants compete within their region. Each region has its own winners and prizes. Within each regional track, participants choose a sub-track (Technical AI Safety, AI Governance/Policy, or a locally-tailored sub-track defined by their hub). If you're based outside the three regions, you can still take part through the Open Track below.
Track 1: Latin America
Hubs in São Paulo, Buenos Aires, Bogotá, México: Merida-Guadalajara. Three winning teams ($3,000 total).
Brazil's AI bill (PL 2.338/2023), approved by the Senate and pending Chamber vote, includes a standalone human rights chapter that goes beyond the EU AI Act. Chile became the first country in the world to constitutionally protect neuro-rights. Colombia's CONPES 4144 established a national AI policy framework in early 2025.
We encourage submissions in three sub-tracks:
Technical safety: AI fairness for Portuguese and Spanish language models, safety evaluations for AI systems deployed in Latin American contexts.
Governance: regulatory analysis of emerging legislation across the region.
Locally-tailored: problems defined by your hub that reflect local context.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 2: Africa
Hub in Cape Town. One winning team ($1,000 total).
Africa faces risks from advanced AI that are not addressed through frontier AI safety efforts. African-context deployment-side risks include deepfake-driven electoral interference, data-colonial dependency on foreign infrastructure, compute and semiconductor scarcity constraining sovereign AI capacity, and large-scale labour market disruptions. This hackathon is an opportunity to prototype African-context solutions for misuse resilience, differential defence acceleration, and mitigating gradual disempowerment.
We encourage submissions in three sub-tracks:
Policy: recommendations grounded in African regulatory and institutional contexts.
Evals and benchmarks: work that builds on existing efforts and transfers to African contexts.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 3: Asia
Hubs in Bengaluru (Electric Sheep), New Delhi (Secure AI Futures Lab), and Vietnam (Hanoi and Ho Chi Minh City). Two winning teams ($2,000 total).
Asia spans the full spectrum of AI governance approaches. India's "Seven Sutras" framework explicitly prioritizes innovation over restraint. China has enacted more sector-specific AI regulations than any other country. Vietnam's AI law took effect in March 2026, the first binding AI legislation in Southeast Asia. The ASEAN Guide on AI Governance and Ethics offers a voluntary regional framework. Projects can address cross-border governance harmonization, safety evaluations for non-English language models, technical AI safety research, or region-specific risk assessments.
We encourage submissions in three sub-tracks:
Governance and geopolitics: AI compliance, AI sovereignty, national data security, compute diffusion and access.
Socio-economic impacts: deepfakes and misinformation, caste bias, algorithmic bias across ethnic minorities, languages, and dialects, AI misdiagnosis in rural healthcare, gig platforms, labor displacement, gradual disempowerment, and cooperative AI.
Technical safety: cybersecurity, multilingual, multimodal, and open-source models, small AI, and on-device AI.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 4: Open
Based outside Latin America, Africa, and Asia? You can still take part. Submit your project to the Open Track and build the same way the regional tracks do: a tool, evaluation, or policy analysis on any AI safety problem that matters to you.
Who should participate?
Founders and entrepreneurs
AI safety researchers and engineers
Machine learning researchers and engineers
Policy researchers working on AI governance
Software engineers interested in safety infrastructure
Security researchers and red teamers
Students and early-career researchers exploring AI safety
Anyone working on AI and its impacts in the Global South
What you will do
Over three days, you will:
Form teams and choose a regional track and sub-track
Research and scope a specific problem using the provided resources
Build a project: a tool, evaluation, policy analysis, or research contribution
Submit a research report (PDF) documenting your approach, results, and implications
Have your work reviewed by judges from AI safety organizations, universities, and policy institutions in your region
What happens next
After the hackathon, all submitted projects are reviewed by expert judges. Top projects receive prizes. The best teams may be invited into the Apart Fellowship for continued research and mentorship (subject to the asterisked caveat in Overview).
Organized by
Apart Research
Local hubs (8):
Latin America: BAISH (Buenos Aires) | EA Brasil (São Paulo) | AI Safety Colombia (Bogotá) | AISMX (Mérida and Guadalajara)
Africa: AI Safety South Africa (Cape Town)
Asia: Electric Sheep (Bengaluru) | Secure AI Futures Lab (New Delhi) | AnToàn.AI (Hanoi and Ho Chi Minh City)
Supported by Schmidt Sciences.
Sign Ups
Entries
Overview
Resources
Guidelines
Schedule
Entries
Overview
HACKATHON WINNERS
Congratulations to our winning teams, and thank you to everyone who submitted. We received 217 projects across three tracks, from hubs and participants across Latin America, Africa, and Asia, with support from Schmidt Sciences. The bar was high throughout. Each regional winner receives $1,000.
🌎 Latin America
🥇 Coldron by Leonardo Párraga, Angie Giraldo & Víctor Gelves
🥇 Probing Latent Colombian Identity Inferences in Qwen2.5-7B with Natural Language Autoencoders by UAO SAFETY
🥇 Thought Anchors for Social Bias: Which Reasoning Steps Matter in Extended Thinking LLMs on Latin American Scenarios by Andres Felipe Mosquera Hernandez
🌏 Asia-Pacific
🥇 STEER: Mech interp-based white box attack on LLMs by Joshua Adrian Cahyono
🥇 Do Multilingual Vision-Language Models Abstain under Cross-Modal Conflict in Low-Resource Languages? by Anvesh Reddy Lankala, Vicky Feliren & Akansh Jain
🌍 Africa
🥇 Confidently Wrong: Measuring and Mitigating Calibration Risks in LLMs for African Languages by Team AIMS South Africa
🎖️ Honorable Mentions
Non-cash recognition for standout work, with these teams under consideration for the Apart Fellowship.
JusticIA
Pragmatic Sophistry in Vietnamese Multi-Agent Oversight
¿Por qué los agentes obedecen?
Local-Geometry Signals of Capability Emergence During Portuguese Grammar Acquisition
IndicViet-Safe
The Shapes of Bias in Spanish-Prompted LLMs and the Debiasing Prompt Scaffolds
Ufakazi
—————————————————————————————————————————————————
The Global South AI Safety Hackathon brings together researchers, engineers, and policy professionals across Latin America, Africa, and Asia to work on AI safety problems that matter most in their regions. Over one weekend, participants build tools, evaluations, and policy research addressing gaps the field has overlooked.
The hackathon is designed for and with the Global South. Participants compete within their region, not globally. The best teams from all regions are invited into the Apart Fellowship for continued research and mentorship.
Why the Global South?
AI safety research is concentrated in a handful of countries. None of the top 100 institutions by AI publication index, in either universities or companies, are based in Africa or Latin America (Chan et al., 2021). Meanwhile, AI risks hit differently in these regions: jailbreaks are more common in low-resource languages, and algorithmic bias trained on non-local data shows up in healthcare and hiring deployments.
This hackathon is not about bringing AI safety to the Global South. It is about bringing the Global South into AI safety. Researchers here have contextual knowledge the field needs: regulatory landscapes, language gaps, and institutional constraints that determine whether safety research actually works in practice.
Regional Tracks
Participants compete within their region. Each region has its own winners and prizes. Within each regional track, participants choose a sub-track (Technical AI Safety, AI Governance/Policy, or a locally-tailored sub-track defined by their hub). If you're based outside the three regions, you can still take part through the Open Track below.
Track 1: Latin America
Hubs in São Paulo, Buenos Aires, Bogotá, México: Merida-Guadalajara. Three winning teams ($3,000 total).
Brazil's AI bill (PL 2.338/2023), approved by the Senate and pending Chamber vote, includes a standalone human rights chapter that goes beyond the EU AI Act. Chile became the first country in the world to constitutionally protect neuro-rights. Colombia's CONPES 4144 established a national AI policy framework in early 2025.
We encourage submissions in three sub-tracks:
Technical safety: AI fairness for Portuguese and Spanish language models, safety evaluations for AI systems deployed in Latin American contexts.
Governance: regulatory analysis of emerging legislation across the region.
Locally-tailored: problems defined by your hub that reflect local context.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 2: Africa
Hub in Cape Town. One winning team ($1,000 total).
Africa faces risks from advanced AI that are not addressed through frontier AI safety efforts. African-context deployment-side risks include deepfake-driven electoral interference, data-colonial dependency on foreign infrastructure, compute and semiconductor scarcity constraining sovereign AI capacity, and large-scale labour market disruptions. This hackathon is an opportunity to prototype African-context solutions for misuse resilience, differential defence acceleration, and mitigating gradual disempowerment.
We encourage submissions in three sub-tracks:
Policy: recommendations grounded in African regulatory and institutional contexts.
Evals and benchmarks: work that builds on existing efforts and transfers to African contexts.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 3: Asia
Hubs in Bengaluru (Electric Sheep), New Delhi (Secure AI Futures Lab), and Vietnam (Hanoi and Ho Chi Minh City). Two winning teams ($2,000 total).
Asia spans the full spectrum of AI governance approaches. India's "Seven Sutras" framework explicitly prioritizes innovation over restraint. China has enacted more sector-specific AI regulations than any other country. Vietnam's AI law took effect in March 2026, the first binding AI legislation in Southeast Asia. The ASEAN Guide on AI Governance and Ethics offers a voluntary regional framework. Projects can address cross-border governance harmonization, safety evaluations for non-English language models, technical AI safety research, or region-specific risk assessments.
We encourage submissions in three sub-tracks:
Governance and geopolitics: AI compliance, AI sovereignty, national data security, compute diffusion and access.
Socio-economic impacts: deepfakes and misinformation, caste bias, algorithmic bias across ethnic minorities, languages, and dialects, AI misdiagnosis in rural healthcare, gig platforms, labor displacement, gradual disempowerment, and cooperative AI.
Technical safety: cybersecurity, multilingual, multimodal, and open-source models, small AI, and on-device AI.
Open: any other project relevant to AI safety in the region that doesn't fit the categories above.
Track 4: Open
Based outside Latin America, Africa, and Asia? You can still take part. Submit your project to the Open Track and build the same way the regional tracks do: a tool, evaluation, or policy analysis on any AI safety problem that matters to you.
Who should participate?
Founders and entrepreneurs
AI safety researchers and engineers
Machine learning researchers and engineers
Policy researchers working on AI governance
Software engineers interested in safety infrastructure
Security researchers and red teamers
Students and early-career researchers exploring AI safety
Anyone working on AI and its impacts in the Global South
What you will do
Over three days, you will:
Form teams and choose a regional track and sub-track
Research and scope a specific problem using the provided resources
Build a project: a tool, evaluation, policy analysis, or research contribution
Submit a research report (PDF) documenting your approach, results, and implications
Have your work reviewed by judges from AI safety organizations, universities, and policy institutions in your region
What happens next
After the hackathon, all submitted projects are reviewed by expert judges. Top projects receive prizes. The best teams may be invited into the Apart Fellowship for continued research and mentorship (subject to the asterisked caveat in Overview).
Organized by
Apart Research
Local hubs (8):
Latin America: BAISH (Buenos Aires) | EA Brasil (São Paulo) | AI Safety Colombia (Bogotá) | AISMX (Mérida and Guadalajara)
Africa: AI Safety South Africa (Cape Town)
Asia: Electric Sheep (Bengaluru) | Secure AI Futures Lab (New Delhi) | AnToàn.AI (Hanoi and Ho Chi Minh City)
Supported by Schmidt Sciences.
Speakers & Collaborators

James Fox
Speaker
James Fox is a Senior Science Associate at Schmidt Sciences, where he leads the Science of Trustworthy AI program and supports the broader mission of the AI and Advanced Computing Institute. Prior to joining Schmidt Sciences, James served as Research Director of the London Initiative for Safe AI (LISA). He earned his DPhil in Computer Science from the University of Oxford, supervised by Tom Everitt, Michael Wooldridge & Alessandro Abate; research on game theory, causality, and reinforcement learning. MSci/BA Natural Sciences (Physics), Cambridge.

Juan Felipe Cerón Uribe
Speaker and Judge
Juan Felipe Cerón Uribe is an AI Alignment Research Engineer at OpenAI in San Francisco, where he works on mitigating existential risks from artificial intelligence. He previously built AI systems at Factored and was a research intern at the Stanford Existential Risks Initiative.

Tan Zhi Xuan
Speaker
Tan Zhi Xuan is a Presidential Young Professor in the NUS Department of Computer Science. Xuan's research focuses on scaling cooperative intelligence via rational and model-based AI, spanning probabilistic programming, model-based planning, Bayesian inference, AI alignment, and computational cognitive science, and leads the Cooperative Systems & Intelligence (CoSI) lab.

Samuel Segun
Speaker and Judge
Dr. Samuel T. Segun is an expert in AI safety, ethics and technical governance, advising governments, multilateral institutions, and research networks on responsible AI. He is an Honorary Senior Lecturer and a Senior Research member of the African Hub on AI Safety, Peace and Security at the University of Cape Town, Editor-in-Chief of The Algorithmic Review, and sits on the Board of Advisors for VerifyWise. Previously he was Senior Consultant on AI Safety to the UN Office of Counter-Terrorism (UNOCT) and UNICRI. He is the author/editor of several articles and books (Palgrave, Nature, Springer, Cambridge), including Selected Issues in the Ethics of AI (2022) and AI, Ethics and Policy Governance in Africa (2024).

Umut Pajaro Velasquez
Speaker and Judge
Umut Pajaro Velasquez is President of the Internet Society Colombia Chapter and holds an MA in Cultural Studies, researching education, digital rights, and ethical AI design and development, with a focus on mitigating bias against marginalized groups. Umut has chaired Internet Governance groups, including the Internet Society Gender Standing Group.

Sang Truong
Speaker
Sang Truong develops foundations for AI Measurement Science, drawing on probabilistic machine learning, measurement theory, and mechanism design to improve how we evaluate AI systems. His work supports the development of AI systems that serve people across diverse backgrounds and needs. He is a PhD candidate in Computer Science at the Stanford AI Lab with Sanmi Koyejo and Nick Haber.

Tianyi Qiu
Speaker and Judge
Tianyi is an alignment researcher at Oxford HAI / Stanford CS and former Anthropic AI Safety Fellow. He develops human-in-the-loop training interventions that make AI foster, not undermine, growth in human ideas. Research projects he led have received two Best Paper Awards (ACL'25; NeurIPS'24 Pluralistic Alignment Workshop).

Akash Kundu
Speaker
Akash Kundu is an AI safety researcher from Kolkata with publications at NeurIPS and ICLR. He has worked with organisations including FAR.AI and Apart Research (as a lab fellow) on AI safety and LLM evaluation, and is currently in the extension phase of the Cooperative AI Research Fellowship.

Amaia Amézaga
Speaker and Judge
Amaia Amézaga is an independent researcher and the founder of Sattva Labs, an initiative dedicated to AI safety, model evaluation, and human-AI interaction. Her approach combines interaction design (HCI), multicultural and multilingual communication, and qualitative analysis to explore how people interpret, use, and relate to artificial intelligence systems.

Carlos Giudice
Speaker
Carlos Giudice is a research engineer at EquiStamp, contracting for Redwood Research on AI control, where he helped build LinuxArena. Before AI safety he spent six years as an ML engineer at MercadoLibre (Latin America's largest e-commerce company) and a year at CERN simulating data-transfer networks. He co-organizes BAISH, the Buenos Aires AI Safety Hub.

Clement Neo
Speaker
Clement Neo works on mechanistic interpretability for AI safety. He is a Lab Advisor at Apart Research and the founder of Neo Research, and was previously a research engineer at the Singapore AI Safety Institute and Nanyang Technological University.

Hieu Vu
Speaker and Judge
An engineer turned independent researcher studying the interpretability of language models.

Jasmine Li
Speaker and Judge
Jasmine is a research scientist at SaferAI and former MATS fellow. She previously worked on evaluation gaming mitigations as a MATS Fellow with Alex Turner, agent security at Gray Swan AI, and LLM honesty with the Center for AI Safety.

Luis Enrique Urtubey De Césaris
Speaker and Judge
Luis Enrique Urtubey De Césaris is Director of Strategy at CEGIA, the Centro de Estudos em Governança de Inteligência Artificial, where he leads work on AI governance and field-building. His current focus areas include PL 2338/2023, Brazil's framework AI bill; the creation of a Brazilian AI Safety Institute; international AI governance coordination; and capacity-building in AI governance and technical AI safety.

Miguel A. Peñaloza
Speaker
Miguel A. Peñaloza is a professional statistician whose work focuses on developing benchmarks to assess the capabilities of Large Language Models (LLMs). Currently, he is designing methodologies aimed at making AI system evaluations more inclusive, representative, and globally accessible.

Naveen Kumar Gond
Speaker
Naveen Kumar Gond is an alumnus of the BASIS AI Safety Policy Fellowship at UC Berkeley with a background in public policy and governance. His focus is on global AI governance and frontier AI risk, particularly how international institutions and national regulators can develop coherent frameworks for advanced AI systems. He is currently building his research and policy practice at the intersection of AI alignment, responsible AI development, and regulatory affairs.

Pradyumna Shyama Prasad
Speaker
Pradyumna Shyama Prasad is an Evaluations Fellow at Elicit, where he works on AI evaluations.

Roshni Lulla
Speaker
Roshni is co-founder and CRO of the Institute for Humane Robotics (IHR), working on guidelines for human-robot interactions, and a neuroscientist (PhD, Brain & Cognitive Sciences, USC, under Antonio Damasio and Jonas Kaplan). Bridges affective neuroscience, moral cognition, and AI safety.

Sissi de la Peña
Speaker
Sissi de la Peña is the Director of The Dot Network and served as a 2024-2025 Tech Policy Fellow at UC Berkeley. She has spent over 20 years in Latin American digital and AI policy, from USMCA digital-trade negotiations to representing major technology companies in regional regulatory forums, and was named Responsible AI Leader of the Year at the 2025 Women in AI Awards.

Srinivas Pochincharla
Speaker and Judge
Srinivas Pochincharla is an engineering leader and Senior Technical Program Manager at Amazon with over 12 years of experience in software engineering, enterprise data architecture, and AI/ML-powered product development. He specializes in leading complex, cross-functional initiatives at the intersection of large-scale data platforms and intelligent automation, with a particular focus on Generative AI and enterprise data transformation.

Valerie Pang
Speaker
Valerie is the Program Manager at Singapore AI Safety Hub where she handles memberships, marketing, events and operations. She has 4 years of experience working in tech companies in the US and Singapore, and 2 years of international non-profit experience working in corporate engagement. She has experience organising events and conferences with hundreds of attendees.

Juan Roberto Hernández Villalobos
Speaker
Juan is an AI consultant for UNESCO. His work spans technology management and communication, with 15 years of experience in innovation, digital transformation, and AI, all with a focus on social impact and human rights.

Janhavi Khindkar
Speaker, Judge and Mentor
Janhavi Khindkar is an Applied AI Researcher and Engineer working on Bhashini, India's national multilingual AI platform under MeitY, where she works on model optimization, fine-tuning, and deployment for low-resource Indic languages at scale. She also leads ValueShift Research, an independent AI safety collaboration focused on mechanistic interpretability and AI control. Her work sits at the intersection of applied ML infrastructure and AI safety, with a particular interest in how safety alignment behaves across languages and cultural contexts.

Hemanth Badabagni
Speaker and Judge
Hemanth Badabagni is a technology leader specializing in data engineering, analytics, and AI-enabled data platforms. His work focuses on data governance, semantic systems, and enterprise AI, with an emphasis on building trusted, scalable foundations for data-driven decision-making.

Isabela Rodrigues Martins
Speaker
Isabela is a cybersecurity professional with four years of experience focused on protecting data and systems. She continues to build her skills through specialized training, including AWS, the Microsoft SC-900 certification (via Womcy LATAM in partnership with Microsoft), and Harvard's CS50 Introduction to Computer Science (offered in Brazil through Fundacao Estudar), which covered JavaScript, Python, CSS, and HTML.

Kamil Alaa
Organizer
Operations at Apart Research, managing research sprints and hackathons.

Ivan Martucci Franco
Hub Organizer EA Brazil
Ivan Martucci Franco is the National Organizer of Effective Altruism Brazil and a specialist audiovisual production, with an MBA in Data Science and Artificial Intelligence. He led the organization of EAGxSão Paulo 2025, the first EAGx in South America, and co-led the moderation tem for EA Connect, the largest online EA conference by attendance.

Tegan Green
Hub Organizer AIS South Africa
I work at AI Safety South Africa, where I run the Cooperative AI Research Fellowship and organise reading groups and other events at our Cape Town hub. My background prior to AI safety is in art, film and UX design - I care a lot about how people experience and interact with the things we build. I'm especially interested in how humans and AI agents navigate shared decision-making and what it looks like to keep humans in the loop as these systems evolve

Nguyen Tran
Hub Organizer AnToàn.AI and Judge
Associate researcher at a Vietnam-based AI Institute. As an international speaker, judge, and mentor with experience at FIRST Robotics and FPT Corporation, they write and work on inclusive AI safety, traversing grassroots organizing, cyber uplift for the global majority, and middle power geopolitics.

Jose Gelves
Hub Organizer AIS Colombia
Jose Gelves is a political scientist and AI governance researcher at Universidad de los Andes. He is Co-Founder at AI Safety Colombia and a Research Consultant on a digital government initiative funded by Colombia’s Ministry of ICT. His work focuses on AI in public institutions and democratic processes, including elections and the labor market.

Max Pinelo
Hub Organizer AIS Mexico and Mentor
Max Pinelo is co-founder of AI Safety Mexico and leads the organization’s strategy.

Isabel Camara
Hub Organizer AIS Mexico
Isabel Camara is co-founder of AI Safety Mexico, with a background in data engineering and public policy. Her main interest is AI governance, where she aims to contribute to building responsible, well-aligned systems through a combination of technical expertise, analytical thinking, and community leadership.

Janeth Valdivia
Hub Organizer AIS Mexico
Janeth Valdivia is a data engineer and economist focused on Technical AI Governance and research.
Head of Operations at AI Safety México, she leads execution and coordination of AI safety programs and initiatives.

Angel Tenorio
Hub Organizer AIS Mexico and Mentor
Angel Tenorio is co-founder of AI Safety Mexico, working as a Senior Software Engineer. Motivated to reduce existential risks from advanced AI models through education and research.

Marco Guzman
Hub Organizer AIS Mexico
Marco is an AI & Data Science student and a Monarch Effect Foundation ambassador. He is the founder of AIS Student Club at Universidad de Guadalajara, campus CUGDL. His main interest lies between AI governance and social impact strategy.

Dexter Gomez
Hub Organizer AIS Mexico
Dexter Gómez is a Senior AI Engineer and researcher at AI Safety Mexico. He focuses on building technical capacity within the community through AI workshops, model experimentation , and alignment research.

Basil Labib
Hub Organizer SAFL
Basil is a MTS at Secure AI Futures Lab (SAFL) working on agentic evaluations and technical governance in India. Basil holds a Masters in CS from IIT Delhi.

Ash Singh
Hub Organizer Electric Sheep
CEO AND founder of Electric Sheep

Diksha Singh
Hub Organizer Electric Sheep
Program Manager at Electric sheep

Aniruddh Bhaduri
Mentor
Aniruddh Bhaduri is an independent AI safety and cybersecurity researcher, primarily working on cyborgism. He is interested in how humanity can use AI tools to rapidly learn, grow, and ultimately evolve. He also has a background and interest in game theory, mechanism design, and EdTech

Isabella Luong
Mentor and Judge
Keywords: Eval, AI Security. RMIT '25 Grad, 3 YOE in Tech & AI Adoption. Five months into AI safety: two NeurIPS conference papers on AI security (FragBench) and Propensity Eval (MANTA), ARENA (Boston), Iliad Intensive (Theoretical Alingment, London).

Trang Pham
Mentor and Judge
Trang Pham is a lecturer at the University of Economics and Law, Vietnam National University Ho Chi Minh City, and holds a PhD in innovation, economics, and governance from UNU-MERIT/Maastricht University. Her research focuses on digitalization, AI, technological change, and inclusive development in Vietnam and the Global South, with published work on mobile internet and socioeconomic outcomes. She is also involved in emerging initiatives on AI governance, development futures, and regional knowledge collaboration across Southeast Asia.

Neeraj Kumar Singh Beshane
Mentor and Judge
Neeraj Beshane is a Staff Security Infrastructure Engineer at Parafin, where he architects Zero Trust security for an $8B+ embedded-finance platform. His peer-reviewed work covers adversarial embedding attacks in RAG systems (EmbedGuard, IJCESEN/Scopus) and tamper-evident AI accountability for EU AI Act Article 14 (RuntimeGuard-AI, JoCAAA).

Haakon Huynh
Mentor and Judge
Haakon Huynh is an AI policy researcher focusing on global compute governance, working with the Oxford Martin School AI Governance Initiative and the Future Economies Kuwait Research lab at Columbia School of International and Public Affairs (SIPA). He draws on experience in international diplomacy at the Norwegian Ministry of Foreign Affairs and the United Nations in Geneva, grounding his policy recommendations in practical feasibility.

Katerine Hernandez
Mentor and Judge
Katerine Hernández is a Colombian business administrator and lawyer specializing in administrative law, AI governance, and the responsible adoption of artificial intelligence in public institutions. Her work focuses on algorithmic accountability, institutional risk, ethical governance, and the impact of AI systems on public decision-making in Latin America. She has contributed to AI literacy initiatives, institutional capacity-building, and responsible innovation in public-sector settings, promoting a human, ethical, and contextual view of artificial intelligence.

Nguyen Duy Tung
Mentor and Judge
Tung Nguyen is a Machine Learning Engineer at a U.S. health-tech startup, with degrees in Mathematics, Physics, and a Master's in Computer Science. His interest spans AI safety, mechanistic interpretability in mathematical reasoning, fairness-aware recommender systems, deep learning, and computer vision, with prior research experience at Microsoft Cloud & AI. He is excited to mentor Global South AI Safety Hackathon participants and support their work toward building interpretable and socially responsible AI systems.

David Williams-King
Mentor and Judge
David has a PhD in cybersecurity from Columbia University, and has been working full-time in AI safety for the past two years. He enjoys mentoring and helping out with research projects, both in his current role at ERA, and recently at the AI Security Bootcamp in Singapore. David loves to travel, especially in Asia, and is always looking for new collaborators for research projects.

Claude Formanek
Mentor and Judge
Claude Formanek completed his undergraduate studies in Mathematics and Computer Science at the University of Cape Town (UCT), where he continued his academic journey to an MSc and eventually PhD. Under the supervision of Jonathan Shock, his doctoral research focused on Multi-Agent Reinforcement Learning (MARL), specifically exploring the challenges of learning from static datasets. He was awarded the Cooperative AI PhD Fellowship in January 2025 and submitted his thesis for examination in January 2026. Now Claude is a research scientist at AI Safety South Africa, where his research focuses on Multi-Agent Safety with frontier models.

Aditya Arpitha Prasad
Mentor and Judge
Aditya works on mentoring and coordinating AI alignment community building efforts. He has worked with CEA, groundless.ai and other organizations in the field. He is passionate about agendas like Live Theory, Agent foundations work by softmax, and building interfaces.

Anusha Mujumdar
Mentor and Judge
Anusha Mujumdar is an independent AI safety researcher, mentor with the Algoverse AI Safety Fellowship and Research Fellow at SPAR (assoc. MIT CSAIL); previously AI research leadership at Intuit; PhD applied mathematics (Exeter); 22 patents and 20+ peer-reviewed papers (AAMAS, IROS, IEEE Transactions).

Amol Walvekar
Judge
Amol is an exited founder (sold an AI-agents-for-finance company); former ML researcher at BU and Stanford; PM at Fortune 100s and startups; currently a scout with General Catalyst, based in San Francisco.

Aditya Thakur
Judge
Aditya Thakur is a Senior Director of Engineering at Salesforce, leading enterprise-scale Quote-to-Cash platform delivery, AI-driven engineering transformation, and operational excellence; passionate about AI governance, scalable systems, developer productivity, and mentoring.

Vivek Kotecha
Judge
Vivek Kotecha is a founding infrastructure engineer at OpusClip (10 yrs production-scale systems); previously Senior Infrastructure Engineer at VMware (Kubernetes, cloud infra, DevOps, reliability).

Hardik Chawla
Judge
Hardik Chawla is a Technical Product Leader with 8+ years of experience building AI/ML systems across supply chain, clinical research, and autonomous mobility at Uber, Amazon, and ZS Associates. His work spans responsible AI governance, predictive modeling, and safety infrastructure deployed at scale across millions of users globally. He has been published in industry outlets on AI adoption and safety, and is passionate about ensuring AI is safe, reliable, and equitable in diverse real-world contexts.

Agni Tripathi
Judge
Agni Tripathi is a Staff Product Manager at Intuit leading AI and agentic systems for TurboTax (~40M US taxpayers), earlier product work at Amazon; focus on trust, audit, and reliability in customer-facing agentic systems.

sushant awasthi
Judge
Sushant is a Big Data and AI/ML Engineer with nearly two decades of experience at Amazon and JPMorgan Chase — engineering data pipelines processing 90 PB daily and production-grade AI systems at enterprise scale — holding a Post Graduate Diploma in Machine Learning and AI from Columbia Engineering's executive education program in partnership with Emeritus.

Nihal K
Judge
Nihal Kaul is a Lead Software Engineer at Revscale AI who builds scalable, cloud-native systems for fast-moving startups. He works across distributed systems, infrastructure, and reliability, with a recent focus on AI systems design, memory infrastructure, and production-grade AI applications that are reliable, adaptive, and useful.

David Salinas
Judge
David Salinas is founder and CEO of Zendly, AI agents that handle sales and support conversations on WhatsApp for enterprises. Before Zendly, he led product at Rappi and Zubale, where he built conversational commerce products used by over 500,000 people across Latin America. He is also cofounder of Soy Startup, a community training Latin American founders to build with AI.

Abhishek Das (Salesforce)
Judge
Abhishek Das is a Staff ML and Distributed Systems Engineer at Salesforce AI Platform, where he leads large-scale DAG-based and agentic inference platforms powering enterprise AI workloads. He has scaled multi-tenant ML inference systems to tens of millions of production requests per day and has deep expertise across distributed systems, ML platforms, cloud architecture, and AI infrastructure. His background includes leadership roles at Salesforce and Microsoft Azure, multiple patents, and extensive experience mentoring engineers and evaluating complex technical systems.

Varun J. Vincent
Judge
Varun J. Vincent is the founder and CEO of FalconFirst AI, where he is building product decision intelligence for Fortune 500 product teams. Previously, eight years at JPMorgan Chase as Head of Product for the Access and Security Manager platform, securing 2.5 million small and medium businesses. He also serves on the board of LIFT-USA, a non-profit that takes students from rural Indian poverty through graduate school, creating a generational impact.

Temi Oloyede
Judge
I am a Software Engineer at Box working on AI infrastructure for enterprise-scale retrieval-augmented generation (RAG) systems, where I design and operate platforms supporting document understanding, semantic search, and agentic workflows. Previously, I worked at Facebook (Meta) contributing to large-scale ranking, retrieval, and ML system infrastructure.

Saraswati Mishra
Judge
Senior Software Engineer specializing in scalable, observable AI infrastructure, with nearly a decade of experience at the intersection of big data systems and LLM workflows. Currently focused on deploying agentic architectures and building observability pipelines for large-scale language model applications. Passionate about designing transparent, reliable, and data-compliant systems that power real-world AI products.

Nikhil Reddy Pallepati
Judge
Nikhil R. Pallepati is a Machine Learning Engineer at Microsoft, where he leads the design of production-scale AI systems including graph neural network-based detection systems and agentic LLM pipelines protecting Azure cloud infrastructure, with prior experience building enterprise ML systems at various Fortune 500 companies.

Wairagala Wakabi
Judge
Wairagala Wakabi, PhD, is an informatician with extensive international experience in technology and innovation research. He works with the Collaboration on International ICT Policy for East & Southern Africa (CIPESA) - www.cipesa.org - a Pan-African digital policy think-tank.

Jady Pamella
Judge
Jady Pamella is an AI engineer and founder based in Stockholm, with 12+ years of experience building production systems across banking, government, research, and startups. She recently worked as an AI Research Engineer at Deep Forestry AB, developing real-time autonomous drone perception with LiDAR point clouds, and is the founder of SoiQet, an LLM-powered platform for social media automation. She holds two master's degrees in AI and IoT from Stockholm University and Cybersecurity from the University of Brasilia, is a Swedish Institute Scholar, and has peer-reviewed research published in Elsevier's Computers & Security.

Syed Anas Mohiuddin
Judge
Syed Anas Mohiuddin is an AI security researcher who built mcp-safeguard, an automated security scanner for Model Context Protocol servers, and used it to responsibly disclose SSRF vulnerabilities in official MCP implementations from Anthropic and Microsoft. He introduced Protocol Pivoting as a novel cross-protocol attack class for multi-agent AI systems.

Soumya Jain
Judge
Soumya Jain is a Research Manager at the Cambridge AI Safety Hub and an AI Product Manager at Terrabase, where she works on enterprise AI agents, evaluations, and trustworthy deployment workflows. She was previously a MARS fellow, researching compute governance and how increasingly capable AI systems may affect enforcement and circumvention dynamics in advanced AI chip export controls. Her broader work sits at the intersection of AI governance, agent safety, and operationalizing safety practices for real-world AI deployment, with a particular interest in Global South contexts.

Vanshika Gupta
Judge
Vanshika Gupta is the founder of ViralCircle and a growth and product marketer focused on helping technology companies grow through clear storytelling and strategic positioning. With a background in computer science and technology management, she brings both technical insight and a creative approach to the AI and startup ecosystem.

Luis Cosio
Judge
Works at the intersection of frontier AI and high-security systems, translating AI safety/security requirements into deployable solutions resilient to real adversaries (nation-state attacks, loss-of-control). Has won multiple Apart hackathons.

Nikita Lokhmachev
Judge
Technical Product Lead, Senior ML Engineer and Co-Founder; Master's in AI, Fulbright. Shifted career focus to AI safety after participating in Apart hackathons.

Cibeles Garcia Burt
Judge
US diplomat with 17 years across Latin America, Africa and Asia. Focused on AI governance; multiple BlueDot courses. Based in Merida, Yucatan.

Vincent Mai
Judge
PhD in ML from Mila; three years as a researcher at Hydro-Quebec (AI for the energy transition); now Senior Research Scientist at LawZero developing technical AI safety solutions.

Camilla Balbis
Judge
Multilingual (EN/ES/IT) professional specialized in AI governance and safety. Research Fellow with AIGS combining risk analysis, technology ethics and international collaboration.

Melissa Robles
Judge
Co-author of SESGO (cultural bias in Spanish-language models) and of a Wayuunaiki translation model. Will evaluate projects on multilingual and cross-cultural behavioral auditing.

Catalina Bernal
Judge
Co-author of SESGO; acknowledged contributor to Eticas' Community Auditing Guide. Will evaluate projects on multilingual and cross-cultural behavioral auditing.

Juan Lievano-Karim
Judge
AI safety researcher. Co-author, with Stuart Russell, of a mentor-assisted reinforcement learning framework aimed at reducing catastrophic risks. Will evaluate projects on AI control and evaluations for agentic systems.

Steve Hege
Judge
Co-founder and Director of ILAPS, leading work on AI, defense and security. Former UN arms embargo investigator. Will evaluate projects on lethal autonomous weapons governance.

Wanda Muñoz
Judge
Specialist in humanitarian disarmament, disability rights and the governance of emerging military technologies. Co-author of work on autonomous weapons, disability, deepfakes and the weaponization of AI. Will evaluate projects on lethal autonomous weapons governance.

Alejandro Acelas
Judge
Researcher focused on AI governance and technical AI safety. Co-author of Computing for Good (European supercomputers for AI) and contributor to the EU GPAI Code of Practice. Will evaluate projects on AI policy and regulation analysis.

Monica Ulloa
Judge
Responsible AI Fellow at BID Lab. Co-author of 'The securitization of artificial intelligence', on how framing AI as a threat shapes its regulation. Will evaluate projects on AI policy and regulation analysis.

Jyoti Lakra
Judge
As an Engineering Leader at Google, I lead the Cloud TPU team within GKE AI Infrastructure, focusing on building and operating the TPU accelerator orchestration stack. This critical infrastructure enables large-scale AI training and inference on the Google Kubernetes Engine, reflecting a strong commitment to advancing AI and cloud technologies. With over ten years of prior experience at AWS and Snowflake, I have contributed to the development and leadership of high-scale distributed systems and managed container services. My expertise encompasses Google Kubernetes Engine (GKE), AI/ML, and TPU, which I leverage to drive innovation, scalability, and efficiency in cutting-edge cloud solutions.

Suneet Malhotra
Judge
Suneet Malhotra is an independent researcher in AI-augmented test automation with 20+ years in software quality engineering. His current work is on multi-agent SDLC orchestration, LLM-as-a-Judge evaluation, and cross-layer observability for agentic systems, with recent peer-reviewed submissions on these topics and open-source companion code at github.com/SuneetMalhotra.

Vashishtha Patil
Judge
Vashishtha Patil is a Senior Applied Scientist at Amazon, developing the next generation of LLM-powered AI capabilities for the Alexa+ Smart Home experience. With 13 years in machine learning spanning Amazon and Qualcomm, he specializes in bringing AI from research to real-world products.

Ashwin Pai
Judge
Ashwin Pai is an engineering leader with over a decade of experience building distributed systems and security products, most recently shipping AI governance and continuous control validation platforms to Fortune 500 customers at RelyanceAI. He was previously CTO of Interfold, a VC-backed fintech startup he built from zero to one.

Gaurav Kumar Sinha
Judge
Gaurav Kumar Sinha is a Senior Principal, Architecture at LTIMindtree and a former Senior Delivery Consultant at AWS Professional Services, with 15+ years architecting enterprise AI/ML and cloud platforms for Fortune 500 companies. A speaker at AWS re:Invent 2025 and author of 35+ publications, he founded SubstrAI, an open-source GenAI infrastructure ecosystem spanning AI-safety guardrails, LLM orchestration, and agent deployment.

San Krish
Judge
Sanjay Krishnegowda is a Data/AI engineer and the creator of agentic-guard, an open-source static analyzer that detects confused-deputy and prompt-injection risks in LLM agent code by modeling the LLM as an adversarially-controlled edge in the taint graph.

Syam Dondapati
Judge
I am an AVP Technical Developer at AIG specializing in database architecture for regulatory compliance across the US, Canada, Brazil, and South Africa, focusing on translating enterprise technology governance into real-world impact.

Tzu Kit Chan
Judge and Mentor
Tzu Kit Chan is Chief of Staff at Atlas Computing and an AGI-preparedness advisor to Southeast Asian decision-makers, and previously founded Caltech AI Alignment and led Stanford AI Alignment.

Yogesh Thanvi
Judge
Yogesh Thanvi is a cloud security and DevSecOps engineer with over fourteen years of experience securing internet-scale distributed infrastructure, holding deployment-approval authority across a global platform of more than 240,000 servers. He is the author of peer-reviewed research published in IEEE on cloud security posture management, Kubernetes admission control, and AI risk, and a named expert reviewer of the ISACA IT Audit Framework (ITAF). He holds the CISA and CDPSE certifications and serves on ISACA's IT Audit and Assurance Advisory Group.

Ankit Arya
Judge
Ankit is Head of AI at Inscope, where he builds AI-native financial reporting systems and works on the practical safety challenges of deploying LLMs in regulated, high-accuracy domains, from prompt injection defenses to evaluation design.

Ksheeraj Sai Vepuri
Judge
Ksheeraj Vepuri is a Senior Research Engineer at Meta Superintelligence Labs, where he leads initiatives in AI safety, alignment, and evaluation for multimodal foundation models. His work spans post-training reinforcement learning, automated red teaming, multimodal safety classifiers, and large-scale evaluation systems that support the safe deployment of generative AI products used by billions of people worldwide.

Ashwin Krishnappa Kumar
Judge
My name is Ashwin and I am a Senior Manager (IT Applications) at Tesla (where I lead a team of 22 engineers) with over 9 years of experience. I have expertise in data engineering, analytics, and AI integration and through my role help organizations make informed decisions swiftly and efficiently. I have also architected scalable data systems and developed user-centric applications that enhance operational performance through my past roles at Tesla (senior Staff Data Engineer, Staff Data Engineer, etc.).

Naga Sujitha Vummaneni
Judge
Naga Sujitha Vummaneni is a Senior Security Engineer at Ripple and Cornell MBA who has secured cloud and AI infrastructure at Google, Nike, and eBay, and publishes IEEE research on LLM and AI security. She authors the AI Security Weekly newsletter and serves as a technical program committee reviewer for IEEE conferences.

Rahul Nambiar
Judge
Building Propensity Labs to study AI model behaviour, specifically those leading to Loss of Control scenarios. Previously, led Data Privacy at Meta and built infrastructure at AWS.

Deepesh Khanna
Judge
Deepesh Khanna is a Technology Leader and an AI researcher with over 16 years of experience in enterprise architecture, artificial intelligence, cloud computing, and technology strategy. His work focuses on AI governance, Agentic AI, cloud-native platforms, compliance automation, and large-scale digital transformation. Deepesh has authored multiple research publications in AI and distributed systems, serves as a technology and innovation judge, and actively contributes to professional communities advancing responsible and scalable AI adoption.

Shantanu Bhatt
Judge
Shantanu Bhatt is a Senior Analyst in Product Security at Salesforce, where he leads enterprise security and compliance initiatives across AI and cloud systems, following prior roles auditing AI/ML and cloud infrastructure at Google. He is also the founder and CEO of iGrow Inc., where he has independently built and launched two AI-powered software platforms.

Surbhi Madan
Judge
Surbhi Madan is a Senior Software Engineer at Google working on the Google Maps AI rendering platforms and infrastructure (focused on AskMaps). She has worked at Google, based in NYC for 8+ years, and is passionate about creating scalable and sustainable platforms for feature teams. She also focuses on growing the next generation of tech talent by mentoring, teaching, and fostering a supportive and collaborative team environment. Surbhi is a graduate of Brown University and is heavily involved in Google's intern hiring program and has mentored several interns in the past.

Vivek Kumar
Judge
Vivek Kumar is an AI Governance Architect and creator of the PAARA framework, a connector-layer methodology for enterprise GenAI governance and AI risk assurance. His work focuses on AI governance, privacy, cybersecurity, agentic AI risk, retrieval-boundary governance, and enterprise AI connector security. He holds AIGP, CIPP/US, CIPP/E, CIPM, CISM, and FIP certifications and serves as IAPP KnowledgeNet Chapter Chair across Philadelphia, New Jersey, and New Delhi.

Juan Djuwadi
Judge
I'm a Product Manager on Google Search, focusing on growth across AI Mode and Search Apps. Previously was a gaming PM across Riot, EA, Niantic, etc.

Vasilii Kondyrev
Judge
Vasiliy is co-founder of Loyal, a confidential compute layer for agentic finance that recently raised $2.5M. He facilitates BlueDot's AGI Strategy course, speaks on AI security, and builds community across the AI safety ecosystem with a network of 300+ researchers, founders, and educators.

Pavel Sikachev
Judge
Pavel Sikachev is a product leader with 10+ years building AI-driven products - recently Chief Product Officer at Jume Platform (an AI-first enterprise company serving Fortune 500 clients including Danone and Unilever) and former Head of Kinship at Mars Petcare. He serves on award juries including the President Tech Award (Uzbekistan) and the CX World Awards (Moscow).

Joanna Wiaterek
Judge
Joanna co-directs the Centre for AI Security and Access, where she leads special projects on governance and financing mechanisms to bridge AI safety and global diffusion. Her work spans AI benefit-sharing to human-centered AI evaluations. Previously, she was a Fellow in the U.S. Congress.

Mark Gaffley
Judge
Mark Gaffley is an admitted attorney (South Africa) with over 13 years of legal & research experience gained through leading local and international organizations. He holds degrees in arts (history and sociology) and law, as well as a PhD in Jurisprudence, all from the University of Cape Town (UCT). His research focuses on the moral implications of artificial intelligence, particularly its effects on human autonomy and independent decision-making. Mark currently holds positions as Director: Legal & Operations at the Global Center on AI Governance; Legal Counsel at Simple.Capital; Honorary Senior Lecturer in the IF Gene RA Group, Department of Medicine, Faculty of Health Sciences, UCT; and Visiting Research Fellow, Southern Centre for Inequality Studies, WITS.

Jesús M. Siqueiros
Judge
His research focuses on participatory modeling, sustainability, and AI. In 2024, he received the Google Academic Research Award for the project Community Weavers of Artificial Intelligence and Nature-based Solutions. He leads the Lab-DEMOSS project, focused on experimenting with methods for integrating AI into social participation.

Amanda Isbosseth Guzmán Aceves
Judge
AI, Data Governance, Public Policies and Emerging Regulations on AI applied to local governments.

Marta Kosmyna
Judge
Marta Kosmyna is a policy expert working on AI governance and international security. Her research background specializes in emerging technologies used in warfare and law enforcement, and civilian protection in conflict zones.

Osmani Redondo
Judge
Director of AI Safety Spain and founder of Women4AISafety Spain. She drives the training and community ecosystem for AI safety within the Spanish-speaking world, connecting talent, resources, and opportunities with the global ecosystem.

Fernando Castillo
Judge
Fernando Castillo is a socio-technical cybersecurity researcher from Mexico working at the intersection of digital security, human rights, democracy, and AI safety. He founded Threat Trackers, a civil-society organization advancing the democratization of cybersecurity for communities underserved by the digital transition.

Marcos Galván López
Judge
Researcher in neurosymbolic artificial intelligence, explainable machine learning, formal reasoning systems, and probabilistic reasoning.

Silvia Fernández Sabido
Judge
Silvia Fernández Sabido is an 'Investigadora por México' fellow affiliated with CentroGeo. She holds a PhD in Physics from Henri Poincaré University (France) and specializes in Natural Language Processing and Computer Science.

Ivete Sánchez Bravo
Judge
PhD Candidate in Administration with a focus on Technological Innovation. Recognized as one of the top 20 AI leaders in Mexico, and recipient of the WAI Awards North America, which spans the United States, Mexico, and Canada. Participated in the Summer School on Responsible AI and Human Rights at Mila.

Germán López-Ardila
Judge
Coordinated the RAM Colombia Report (https://www.unesco.org/es/articles/colombia-avanza-hacia-una-inteligencia-artificial-etica-con-la-presentacion-del-informe-ram-de-la) (UNESCO, 2025) on the country's capacity to govern AI, and facilitates the UNESCO course AI Literacy for Public Servants (https://www.unesco.org/es/articles/fortaleciendo-las-capacidades-publicas-en-inteligencia-artificial-en-america-latina-una-alianza).

Diego Ortiz Barbosa
Judge
Co-author of CHAI (https://arxiv.org/abs/2510.00181) (SaTML 2026), prompt injection via fake visual cues in the environment that hijacks multimodal agents in drones, cars, and robots.

Diego Gomez
Judge
Works on multimodal LLM safety at YouTube and is developing a mechanistic interpretability project on persona vectors at BlueDot Impact (https://bluedot.org).

Maria Paula Mujica
Judge
Leads UNDP's Artificial Intelligence Landscape Assessment (https://www.undp.org/digital/aila) (AILA) across 16+ Global South countries. Co-author of the Ethical Framework for AI in Colombia (https://dapre.presidencia.gov.co/TD/MARCO-ETICO-PARA-LA-INTELIGENCIA-ARTIFICIAL-EN-COLOMBIA-2021.pdf).

Rajanikant Vellaturi
Judge
Rajanikantarao Vellaturi is an enterprise AI and data systems architect with more than 20 years of experience designing and operationalizing large-scale data, analytics, and artificial intelligence platforms. He has led critical data and AI initiatives across organizations including Apple, Kaiser Permanente, Cloudera, and Snowflake, with expertise in enterprise AI systems, cloud data architecture, data engineering, and AI-driven business transformation.

Phani Harish Wajjala
Judge
Phani Harish Wajjala is a Principal Machine Learning Engineer at Roblox, where he leads the ML decisioning layer that classifies and moderates millions of user-generated 3D assets. His work spans content-moderation evaluation, multimodal/VLM pipelines, and model calibration at production scale, backed by five U.S. patents and a CVPR 2026 workshop publication in the area.

Linh Nguyen
Judge
Linh Nguyen is an independent AI researcher and a recognized Google Developer Expert (GDE) in AI/ML, currently serving as the Head of AI at Obello, SF. Her recent contributions to the field include a top 25% submission with the Apart Research sprint and a co-authored paper accepted at an ICML 2026 workshop. Additionally, she is an active academic author with significant publications in journals such as Knowledge-Based Systems and Information Fusion.

Ajay Devineni
Judge
Ajay Devineni is a Senior SRE/DevOps Engineer and AI-SRE researcher with 13+ years of experience in cloud-native financial infrastructure. He is an IEEE Senior Member, AWS Community Builder, and creator of agentsre (https://github.com/Ajay150313/agentsre) an open-source Python library for AI-driven site reliability engineering. His research includes two accepted IEEE papers on intelligent incident prediction and LLM-based regulatory compliance automation in financial DevOps environments.

Venkata Sangaraju
Judge
Venkata Sangaraju is an AI, data, and analytics architect specializing in enterprise-scale data platforms, business intelligence, and AI-driven systems. His expertise spans AI governance, data architecture, information security, and responsible AI adoption. He is an invited speaker at Google Cloud Next 2026 and specializes in applying AI and data technologies.

David Mazumdar
Judge
David Mazumdar is a technology leader with 19+ years of experience evaluating and implementing enterprise AI, automation, and digital transformation solutions across global organizations. He has led large-scale AI enterprise solutions at Uber, General Motors and US Bank. David holds executive credentials in AI and leadership from MIT, Wharton, and Harvard Business School, and he is passionate about advancing responsible, scalable AI adoption.

Jonathan Ng
Judge
Jonathan Ng is an ML researcher and research engineer working on compute verification. He has also worked as a Research Engineer at Apart Research and Cadenza Labs, bringing experience across machine learning, software engineering, and AI safety research.

Royston Monteiro
Judge
Royston Pramod Monteiro is an Engineering Leader at Meta/Facebook, driving the technical development and scaling of Facebook Stories, growing it from Zero to a Billion users. With a background engineering complex systems at Goldman Sachs, Oracle, and Morgan Stanley, his current work explores the practical application of frontier large language models in developing autonomous agents. He holds a Master's degree from NYU.

Suprita Shankar
Judge
Suprita is an ML engineer on Apple's Foundation Models team, designing experiments to understand how data composition affects model performance. Previously, she was a tech-lead manager at Snorkel AI and a Founding Engineer at an Ed-tech startup.

Anchit Jhingan
Judge
Anchit Jhingan is a Senior Data Scientist with over 6 years of experience in big tech, specializing in machine learning, AI systems, and analytics. He currently works at Amazon Prime Video in the content localization domain. His work focuses on building intelligent systems to solve real-world business problems, particularly in media and entertainment.

Pratham Patkar
Judge
Pratham Patkar is Director of Business Systems at Society for Science, where he leads enterprise data architecture, AI readiness strategy, and data governance across the organization's many initiatives, including STEM research competitions, science education outreach, and science news publishing. He has designed data governance frameworks addressing GDPR, CCPA, and COPPA compliance, and has published research on constituent-first data governance for mission-driven organizations. His work explores how nonprofits can adopt AI responsibly without compromising the trust and data protection obligations they hold toward vulnerable constituent populations.

Michelle Malonza
Judge
Michelle is a Research Associate at ILINA, where she pursues two strands of work: the governance of AI in Global South countries, and the governance of AI agents in general. She also serves as Head of Policy, leading efforts to integrate AI safety considerations into African governments' AI decision-making. Her research includes work on the role of Global South countries in safe AI development and an analysis of the risks of automation-first AI adoption in these regions. Previously, Michelle was an AI Futures Fellow and Visiting Researcher at the Centre for the Study of Existential Risk (CSER). She holds an undergraduate law degree from Strathmore University and a Master of Laws degree from Columbia Law School.
Speakers & Collaborators
James Fox
Speaker
James Fox is a Senior Science Associate at Schmidt Sciences, where he leads the Science of Trustworthy AI program and supports the broader mission of the AI and Advanced Computing Institute. Prior to joining Schmidt Sciences, James served as Research Director of the London Initiative for Safe AI (LISA). He earned his DPhil in Computer Science from the University of Oxford, supervised by Tom Everitt, Michael Wooldridge & Alessandro Abate; research on game theory, causality, and reinforcement learning. MSci/BA Natural Sciences (Physics), Cambridge.
Juan Felipe Cerón Uribe
Speaker and Judge
Juan Felipe Cerón Uribe is an AI Alignment Research Engineer at OpenAI in San Francisco, where he works on mitigating existential risks from artificial intelligence. He previously built AI systems at Factored and was a research intern at the Stanford Existential Risks Initiative.
Tan Zhi Xuan
Speaker
Tan Zhi Xuan is a Presidential Young Professor in the NUS Department of Computer Science. Xuan's research focuses on scaling cooperative intelligence via rational and model-based AI, spanning probabilistic programming, model-based planning, Bayesian inference, AI alignment, and computational cognitive science, and leads the Cooperative Systems & Intelligence (CoSI) lab.
Samuel Segun
Speaker and Judge
Dr. Samuel T. Segun is an expert in AI safety, ethics and technical governance, advising governments, multilateral institutions, and research networks on responsible AI. He is an Honorary Senior Lecturer and a Senior Research member of the African Hub on AI Safety, Peace and Security at the University of Cape Town, Editor-in-Chief of The Algorithmic Review, and sits on the Board of Advisors for VerifyWise. Previously he was Senior Consultant on AI Safety to the UN Office of Counter-Terrorism (UNOCT) and UNICRI. He is the author/editor of several articles and books (Palgrave, Nature, Springer, Cambridge), including Selected Issues in the Ethics of AI (2022) and AI, Ethics and Policy Governance in Africa (2024).
Umut Pajaro Velasquez
Speaker and Judge
Umut Pajaro Velasquez is President of the Internet Society Colombia Chapter and holds an MA in Cultural Studies, researching education, digital rights, and ethical AI design and development, with a focus on mitigating bias against marginalized groups. Umut has chaired Internet Governance groups, including the Internet Society Gender Standing Group.
Sang Truong
Speaker
Sang Truong develops foundations for AI Measurement Science, drawing on probabilistic machine learning, measurement theory, and mechanism design to improve how we evaluate AI systems. His work supports the development of AI systems that serve people across diverse backgrounds and needs. He is a PhD candidate in Computer Science at the Stanford AI Lab with Sanmi Koyejo and Nick Haber.
Tianyi Qiu
Speaker and Judge
Tianyi is an alignment researcher at Oxford HAI / Stanford CS and former Anthropic AI Safety Fellow. He develops human-in-the-loop training interventions that make AI foster, not undermine, growth in human ideas. Research projects he led have received two Best Paper Awards (ACL'25; NeurIPS'24 Pluralistic Alignment Workshop).
Akash Kundu
Speaker
Akash Kundu is an AI safety researcher from Kolkata with publications at NeurIPS and ICLR. He has worked with organisations including FAR.AI and Apart Research (as a lab fellow) on AI safety and LLM evaluation, and is currently in the extension phase of the Cooperative AI Research Fellowship.
Amaia Amézaga
Speaker and Judge
Amaia Amézaga is an independent researcher and the founder of Sattva Labs, an initiative dedicated to AI safety, model evaluation, and human-AI interaction. Her approach combines interaction design (HCI), multicultural and multilingual communication, and qualitative analysis to explore how people interpret, use, and relate to artificial intelligence systems.
Carlos Giudice
Speaker
Carlos Giudice is a research engineer at EquiStamp, contracting for Redwood Research on AI control, where he helped build LinuxArena. Before AI safety he spent six years as an ML engineer at MercadoLibre (Latin America's largest e-commerce company) and a year at CERN simulating data-transfer networks. He co-organizes BAISH, the Buenos Aires AI Safety Hub.
Clement Neo
Speaker
Clement Neo works on mechanistic interpretability for AI safety. He is a Lab Advisor at Apart Research and the founder of Neo Research, and was previously a research engineer at the Singapore AI Safety Institute and Nanyang Technological University.
Hieu Vu
Speaker and Judge
An engineer turned independent researcher studying the interpretability of language models.
Jasmine Li
Speaker and Judge
Jasmine is a research scientist at SaferAI and former MATS fellow. She previously worked on evaluation gaming mitigations as a MATS Fellow with Alex Turner, agent security at Gray Swan AI, and LLM honesty with the Center for AI Safety.
Luis Enrique Urtubey De Césaris
Speaker and Judge
Luis Enrique Urtubey De Césaris is Director of Strategy at CEGIA, the Centro de Estudos em Governança de Inteligência Artificial, where he leads work on AI governance and field-building. His current focus areas include PL 2338/2023, Brazil's framework AI bill; the creation of a Brazilian AI Safety Institute; international AI governance coordination; and capacity-building in AI governance and technical AI safety.
Miguel A. Peñaloza
Speaker
Miguel A. Peñaloza is a professional statistician whose work focuses on developing benchmarks to assess the capabilities of Large Language Models (LLMs). Currently, he is designing methodologies aimed at making AI system evaluations more inclusive, representative, and globally accessible.
Naveen Kumar Gond
Speaker
Naveen Kumar Gond is an alumnus of the BASIS AI Safety Policy Fellowship at UC Berkeley with a background in public policy and governance. His focus is on global AI governance and frontier AI risk, particularly how international institutions and national regulators can develop coherent frameworks for advanced AI systems. He is currently building his research and policy practice at the intersection of AI alignment, responsible AI development, and regulatory affairs.
Pradyumna Shyama Prasad
Speaker
Pradyumna Shyama Prasad is an Evaluations Fellow at Elicit, where he works on AI evaluations.
Roshni Lulla
Speaker
Roshni is co-founder and CRO of the Institute for Humane Robotics (IHR), working on guidelines for human-robot interactions, and a neuroscientist (PhD, Brain & Cognitive Sciences, USC, under Antonio Damasio and Jonas Kaplan). Bridges affective neuroscience, moral cognition, and AI safety.
Sissi de la Peña
Speaker
Sissi de la Peña is the Director of The Dot Network and served as a 2024-2025 Tech Policy Fellow at UC Berkeley. She has spent over 20 years in Latin American digital and AI policy, from USMCA digital-trade negotiations to representing major technology companies in regional regulatory forums, and was named Responsible AI Leader of the Year at the 2025 Women in AI Awards.
Srinivas Pochincharla
Speaker and Judge
Srinivas Pochincharla is an engineering leader and Senior Technical Program Manager at Amazon with over 12 years of experience in software engineering, enterprise data architecture, and AI/ML-powered product development. He specializes in leading complex, cross-functional initiatives at the intersection of large-scale data platforms and intelligent automation, with a particular focus on Generative AI and enterprise data transformation.
Valerie Pang
Speaker
Valerie is the Program Manager at Singapore AI Safety Hub where she handles memberships, marketing, events and operations. She has 4 years of experience working in tech companies in the US and Singapore, and 2 years of international non-profit experience working in corporate engagement. She has experience organising events and conferences with hundreds of attendees.
Juan Roberto Hernández Villalobos
Speaker
Juan is an AI consultant for UNESCO. His work spans technology management and communication, with 15 years of experience in innovation, digital transformation, and AI, all with a focus on social impact and human rights.
Janhavi Khindkar
Speaker, Judge and Mentor
Janhavi Khindkar is an Applied AI Researcher and Engineer working on Bhashini, India's national multilingual AI platform under MeitY, where she works on model optimization, fine-tuning, and deployment for low-resource Indic languages at scale. She also leads ValueShift Research, an independent AI safety collaboration focused on mechanistic interpretability and AI control. Her work sits at the intersection of applied ML infrastructure and AI safety, with a particular interest in how safety alignment behaves across languages and cultural contexts.
Hemanth Badabagni
Speaker and Judge
Hemanth Badabagni is a technology leader specializing in data engineering, analytics, and AI-enabled data platforms. His work focuses on data governance, semantic systems, and enterprise AI, with an emphasis on building trusted, scalable foundations for data-driven decision-making.
Isabela Rodrigues Martins
Speaker
Isabela is a cybersecurity professional with four years of experience focused on protecting data and systems. She continues to build her skills through specialized training, including AWS, the Microsoft SC-900 certification (via Womcy LATAM in partnership with Microsoft), and Harvard's CS50 Introduction to Computer Science (offered in Brazil through Fundacao Estudar), which covered JavaScript, Python, CSS, and HTML.
Kamil Alaa
Organizer
Operations at Apart Research, managing research sprints and hackathons.
Ivan Martucci Franco
Hub Organizer EA Brazil
Ivan Martucci Franco is the National Organizer of Effective Altruism Brazil and a specialist audiovisual production, with an MBA in Data Science and Artificial Intelligence. He led the organization of EAGxSão Paulo 2025, the first EAGx in South America, and co-led the moderation tem for EA Connect, the largest online EA conference by attendance.
Tegan Green
Hub Organizer AIS South Africa
I work at AI Safety South Africa, where I run the Cooperative AI Research Fellowship and organise reading groups and other events at our Cape Town hub. My background prior to AI safety is in art, film and UX design - I care a lot about how people experience and interact with the things we build. I'm especially interested in how humans and AI agents navigate shared decision-making and what it looks like to keep humans in the loop as these systems evolve
Nguyen Tran
Hub Organizer AnToàn.AI and Judge
Associate researcher at a Vietnam-based AI Institute. As an international speaker, judge, and mentor with experience at FIRST Robotics and FPT Corporation, they write and work on inclusive AI safety, traversing grassroots organizing, cyber uplift for the global majority, and middle power geopolitics.
Jose Gelves
Hub Organizer AIS Colombia
Jose Gelves is a political scientist and AI governance researcher at Universidad de los Andes. He is Co-Founder at AI Safety Colombia and a Research Consultant on a digital government initiative funded by Colombia’s Ministry of ICT. His work focuses on AI in public institutions and democratic processes, including elections and the labor market.
Max Pinelo
Hub Organizer AIS Mexico and Mentor
Max Pinelo is co-founder of AI Safety Mexico and leads the organization’s strategy.
Isabel Camara
Hub Organizer AIS Mexico
Isabel Camara is co-founder of AI Safety Mexico, with a background in data engineering and public policy. Her main interest is AI governance, where she aims to contribute to building responsible, well-aligned systems through a combination of technical expertise, analytical thinking, and community leadership.
Janeth Valdivia
Hub Organizer AIS Mexico
Janeth Valdivia is a data engineer and economist focused on Technical AI Governance and research.
Head of Operations at AI Safety México, she leads execution and coordination of AI safety programs and initiatives.
Angel Tenorio
Hub Organizer AIS Mexico and Mentor
Angel Tenorio is co-founder of AI Safety Mexico, working as a Senior Software Engineer. Motivated to reduce existential risks from advanced AI models through education and research.
Marco Guzman
Hub Organizer AIS Mexico
Marco is an AI & Data Science student and a Monarch Effect Foundation ambassador. He is the founder of AIS Student Club at Universidad de Guadalajara, campus CUGDL. His main interest lies between AI governance and social impact strategy.
Dexter Gomez
Hub Organizer AIS Mexico
Dexter Gómez is a Senior AI Engineer and researcher at AI Safety Mexico. He focuses on building technical capacity within the community through AI workshops, model experimentation , and alignment research.
Basil Labib
Hub Organizer SAFL
Basil is a MTS at Secure AI Futures Lab (SAFL) working on agentic evaluations and technical governance in India. Basil holds a Masters in CS from IIT Delhi.
Ash Singh
Hub Organizer Electric Sheep
CEO AND founder of Electric Sheep
Diksha Singh
Hub Organizer Electric Sheep
Program Manager at Electric sheep
Aniruddh Bhaduri
Mentor
Aniruddh Bhaduri is an independent AI safety and cybersecurity researcher, primarily working on cyborgism. He is interested in how humanity can use AI tools to rapidly learn, grow, and ultimately evolve. He also has a background and interest in game theory, mechanism design, and EdTech
Isabella Luong
Mentor and Judge
Keywords: Eval, AI Security. RMIT '25 Grad, 3 YOE in Tech & AI Adoption. Five months into AI safety: two NeurIPS conference papers on AI security (FragBench) and Propensity Eval (MANTA), ARENA (Boston), Iliad Intensive (Theoretical Alingment, London).
Trang Pham
Mentor and Judge
Trang Pham is a lecturer at the University of Economics and Law, Vietnam National University Ho Chi Minh City, and holds a PhD in innovation, economics, and governance from UNU-MERIT/Maastricht University. Her research focuses on digitalization, AI, technological change, and inclusive development in Vietnam and the Global South, with published work on mobile internet and socioeconomic outcomes. She is also involved in emerging initiatives on AI governance, development futures, and regional knowledge collaboration across Southeast Asia.
Neeraj Kumar Singh Beshane
Mentor and Judge
Neeraj Beshane is a Staff Security Infrastructure Engineer at Parafin, where he architects Zero Trust security for an $8B+ embedded-finance platform. His peer-reviewed work covers adversarial embedding attacks in RAG systems (EmbedGuard, IJCESEN/Scopus) and tamper-evident AI accountability for EU AI Act Article 14 (RuntimeGuard-AI, JoCAAA).
Haakon Huynh
Mentor and Judge
Haakon Huynh is an AI policy researcher focusing on global compute governance, working with the Oxford Martin School AI Governance Initiative and the Future Economies Kuwait Research lab at Columbia School of International and Public Affairs (SIPA). He draws on experience in international diplomacy at the Norwegian Ministry of Foreign Affairs and the United Nations in Geneva, grounding his policy recommendations in practical feasibility.
Katerine Hernandez
Mentor and Judge
Katerine Hernández is a Colombian business administrator and lawyer specializing in administrative law, AI governance, and the responsible adoption of artificial intelligence in public institutions. Her work focuses on algorithmic accountability, institutional risk, ethical governance, and the impact of AI systems on public decision-making in Latin America. She has contributed to AI literacy initiatives, institutional capacity-building, and responsible innovation in public-sector settings, promoting a human, ethical, and contextual view of artificial intelligence.
Nguyen Duy Tung
Mentor and Judge
Tung Nguyen is a Machine Learning Engineer at a U.S. health-tech startup, with degrees in Mathematics, Physics, and a Master's in Computer Science. His interest spans AI safety, mechanistic interpretability in mathematical reasoning, fairness-aware recommender systems, deep learning, and computer vision, with prior research experience at Microsoft Cloud & AI. He is excited to mentor Global South AI Safety Hackathon participants and support their work toward building interpretable and socially responsible AI systems.
David Williams-King
Mentor and Judge
David has a PhD in cybersecurity from Columbia University, and has been working full-time in AI safety for the past two years. He enjoys mentoring and helping out with research projects, both in his current role at ERA, and recently at the AI Security Bootcamp in Singapore. David loves to travel, especially in Asia, and is always looking for new collaborators for research projects.
Claude Formanek
Mentor and Judge
Claude Formanek completed his undergraduate studies in Mathematics and Computer Science at the University of Cape Town (UCT), where he continued his academic journey to an MSc and eventually PhD. Under the supervision of Jonathan Shock, his doctoral research focused on Multi-Agent Reinforcement Learning (MARL), specifically exploring the challenges of learning from static datasets. He was awarded the Cooperative AI PhD Fellowship in January 2025 and submitted his thesis for examination in January 2026. Now Claude is a research scientist at AI Safety South Africa, where his research focuses on Multi-Agent Safety with frontier models.
Aditya Arpitha Prasad
Mentor and Judge
Aditya works on mentoring and coordinating AI alignment community building efforts. He has worked with CEA, groundless.ai and other organizations in the field. He is passionate about agendas like Live Theory, Agent foundations work by softmax, and building interfaces.
Anusha Mujumdar
Mentor and Judge
Anusha Mujumdar is an independent AI safety researcher, mentor with the Algoverse AI Safety Fellowship and Research Fellow at SPAR (assoc. MIT CSAIL); previously AI research leadership at Intuit; PhD applied mathematics (Exeter); 22 patents and 20+ peer-reviewed papers (AAMAS, IROS, IEEE Transactions).
Amol Walvekar
Judge
Amol is an exited founder (sold an AI-agents-for-finance company); former ML researcher at BU and Stanford; PM at Fortune 100s and startups; currently a scout with General Catalyst, based in San Francisco.
Aditya Thakur
Judge
Aditya Thakur is a Senior Director of Engineering at Salesforce, leading enterprise-scale Quote-to-Cash platform delivery, AI-driven engineering transformation, and operational excellence; passionate about AI governance, scalable systems, developer productivity, and mentoring.
Vivek Kotecha
Judge
Vivek Kotecha is a founding infrastructure engineer at OpusClip (10 yrs production-scale systems); previously Senior Infrastructure Engineer at VMware (Kubernetes, cloud infra, DevOps, reliability).
Hardik Chawla
Judge
Hardik Chawla is a Technical Product Leader with 8+ years of experience building AI/ML systems across supply chain, clinical research, and autonomous mobility at Uber, Amazon, and ZS Associates. His work spans responsible AI governance, predictive modeling, and safety infrastructure deployed at scale across millions of users globally. He has been published in industry outlets on AI adoption and safety, and is passionate about ensuring AI is safe, reliable, and equitable in diverse real-world contexts.
Agni Tripathi
Judge
Agni Tripathi is a Staff Product Manager at Intuit leading AI and agentic systems for TurboTax (~40M US taxpayers), earlier product work at Amazon; focus on trust, audit, and reliability in customer-facing agentic systems.
sushant awasthi
Judge
Sushant is a Big Data and AI/ML Engineer with nearly two decades of experience at Amazon and JPMorgan Chase — engineering data pipelines processing 90 PB daily and production-grade AI systems at enterprise scale — holding a Post Graduate Diploma in Machine Learning and AI from Columbia Engineering's executive education program in partnership with Emeritus.
Nihal K
Judge
Nihal Kaul is a Lead Software Engineer at Revscale AI who builds scalable, cloud-native systems for fast-moving startups. He works across distributed systems, infrastructure, and reliability, with a recent focus on AI systems design, memory infrastructure, and production-grade AI applications that are reliable, adaptive, and useful.
David Salinas
Judge
David Salinas is founder and CEO of Zendly, AI agents that handle sales and support conversations on WhatsApp for enterprises. Before Zendly, he led product at Rappi and Zubale, where he built conversational commerce products used by over 500,000 people across Latin America. He is also cofounder of Soy Startup, a community training Latin American founders to build with AI.
Abhishek Das (Salesforce)
Judge
Abhishek Das is a Staff ML and Distributed Systems Engineer at Salesforce AI Platform, where he leads large-scale DAG-based and agentic inference platforms powering enterprise AI workloads. He has scaled multi-tenant ML inference systems to tens of millions of production requests per day and has deep expertise across distributed systems, ML platforms, cloud architecture, and AI infrastructure. His background includes leadership roles at Salesforce and Microsoft Azure, multiple patents, and extensive experience mentoring engineers and evaluating complex technical systems.
Varun J. Vincent
Judge
Varun J. Vincent is the founder and CEO of FalconFirst AI, where he is building product decision intelligence for Fortune 500 product teams. Previously, eight years at JPMorgan Chase as Head of Product for the Access and Security Manager platform, securing 2.5 million small and medium businesses. He also serves on the board of LIFT-USA, a non-profit that takes students from rural Indian poverty through graduate school, creating a generational impact.
Temi Oloyede
Judge
I am a Software Engineer at Box working on AI infrastructure for enterprise-scale retrieval-augmented generation (RAG) systems, where I design and operate platforms supporting document understanding, semantic search, and agentic workflows. Previously, I worked at Facebook (Meta) contributing to large-scale ranking, retrieval, and ML system infrastructure.
Saraswati Mishra
Judge
Senior Software Engineer specializing in scalable, observable AI infrastructure, with nearly a decade of experience at the intersection of big data systems and LLM workflows. Currently focused on deploying agentic architectures and building observability pipelines for large-scale language model applications. Passionate about designing transparent, reliable, and data-compliant systems that power real-world AI products.
Nikhil Reddy Pallepati
Judge
Nikhil R. Pallepati is a Machine Learning Engineer at Microsoft, where he leads the design of production-scale AI systems including graph neural network-based detection systems and agentic LLM pipelines protecting Azure cloud infrastructure, with prior experience building enterprise ML systems at various Fortune 500 companies.
Wairagala Wakabi
Judge
Wairagala Wakabi, PhD, is an informatician with extensive international experience in technology and innovation research. He works with the Collaboration on International ICT Policy for East & Southern Africa (CIPESA) - www.cipesa.org - a Pan-African digital policy think-tank.
Jady Pamella
Judge
Jady Pamella is an AI engineer and founder based in Stockholm, with 12+ years of experience building production systems across banking, government, research, and startups. She recently worked as an AI Research Engineer at Deep Forestry AB, developing real-time autonomous drone perception with LiDAR point clouds, and is the founder of SoiQet, an LLM-powered platform for social media automation. She holds two master's degrees in AI and IoT from Stockholm University and Cybersecurity from the University of Brasilia, is a Swedish Institute Scholar, and has peer-reviewed research published in Elsevier's Computers & Security.
Syed Anas Mohiuddin
Judge
Syed Anas Mohiuddin is an AI security researcher who built mcp-safeguard, an automated security scanner for Model Context Protocol servers, and used it to responsibly disclose SSRF vulnerabilities in official MCP implementations from Anthropic and Microsoft. He introduced Protocol Pivoting as a novel cross-protocol attack class for multi-agent AI systems.
Soumya Jain
Judge
Soumya Jain is a Research Manager at the Cambridge AI Safety Hub and an AI Product Manager at Terrabase, where she works on enterprise AI agents, evaluations, and trustworthy deployment workflows. She was previously a MARS fellow, researching compute governance and how increasingly capable AI systems may affect enforcement and circumvention dynamics in advanced AI chip export controls. Her broader work sits at the intersection of AI governance, agent safety, and operationalizing safety practices for real-world AI deployment, with a particular interest in Global South contexts.
Vanshika Gupta
Judge
Vanshika Gupta is the founder of ViralCircle and a growth and product marketer focused on helping technology companies grow through clear storytelling and strategic positioning. With a background in computer science and technology management, she brings both technical insight and a creative approach to the AI and startup ecosystem.
Luis Cosio
Judge
Works at the intersection of frontier AI and high-security systems, translating AI safety/security requirements into deployable solutions resilient to real adversaries (nation-state attacks, loss-of-control). Has won multiple Apart hackathons.
Nikita Lokhmachev
Judge
Technical Product Lead, Senior ML Engineer and Co-Founder; Master's in AI, Fulbright. Shifted career focus to AI safety after participating in Apart hackathons.
Cibeles Garcia Burt
Judge
US diplomat with 17 years across Latin America, Africa and Asia. Focused on AI governance; multiple BlueDot courses. Based in Merida, Yucatan.
Vincent Mai
Judge
PhD in ML from Mila; three years as a researcher at Hydro-Quebec (AI for the energy transition); now Senior Research Scientist at LawZero developing technical AI safety solutions.
Camilla Balbis
Judge
Multilingual (EN/ES/IT) professional specialized in AI governance and safety. Research Fellow with AIGS combining risk analysis, technology ethics and international collaboration.
Melissa Robles
Judge
Co-author of SESGO (cultural bias in Spanish-language models) and of a Wayuunaiki translation model. Will evaluate projects on multilingual and cross-cultural behavioral auditing.
Catalina Bernal
Judge
Co-author of SESGO; acknowledged contributor to Eticas' Community Auditing Guide. Will evaluate projects on multilingual and cross-cultural behavioral auditing.
Juan Lievano-Karim
Judge
AI safety researcher. Co-author, with Stuart Russell, of a mentor-assisted reinforcement learning framework aimed at reducing catastrophic risks. Will evaluate projects on AI control and evaluations for agentic systems.
Steve Hege
Judge
Co-founder and Director of ILAPS, leading work on AI, defense and security. Former UN arms embargo investigator. Will evaluate projects on lethal autonomous weapons governance.
Wanda Muñoz
Judge
Specialist in humanitarian disarmament, disability rights and the governance of emerging military technologies. Co-author of work on autonomous weapons, disability, deepfakes and the weaponization of AI. Will evaluate projects on lethal autonomous weapons governance.
Alejandro Acelas
Judge
Researcher focused on AI governance and technical AI safety. Co-author of Computing for Good (European supercomputers for AI) and contributor to the EU GPAI Code of Practice. Will evaluate projects on AI policy and regulation analysis.
Monica Ulloa
Judge
Responsible AI Fellow at BID Lab. Co-author of 'The securitization of artificial intelligence', on how framing AI as a threat shapes its regulation. Will evaluate projects on AI policy and regulation analysis.
Jyoti Lakra
Judge
As an Engineering Leader at Google, I lead the Cloud TPU team within GKE AI Infrastructure, focusing on building and operating the TPU accelerator orchestration stack. This critical infrastructure enables large-scale AI training and inference on the Google Kubernetes Engine, reflecting a strong commitment to advancing AI and cloud technologies. With over ten years of prior experience at AWS and Snowflake, I have contributed to the development and leadership of high-scale distributed systems and managed container services. My expertise encompasses Google Kubernetes Engine (GKE), AI/ML, and TPU, which I leverage to drive innovation, scalability, and efficiency in cutting-edge cloud solutions.
Suneet Malhotra
Judge
Suneet Malhotra is an independent researcher in AI-augmented test automation with 20+ years in software quality engineering. His current work is on multi-agent SDLC orchestration, LLM-as-a-Judge evaluation, and cross-layer observability for agentic systems, with recent peer-reviewed submissions on these topics and open-source companion code at github.com/SuneetMalhotra.
Vashishtha Patil
Judge
Vashishtha Patil is a Senior Applied Scientist at Amazon, developing the next generation of LLM-powered AI capabilities for the Alexa+ Smart Home experience. With 13 years in machine learning spanning Amazon and Qualcomm, he specializes in bringing AI from research to real-world products.
Ashwin Pai
Judge
Ashwin Pai is an engineering leader with over a decade of experience building distributed systems and security products, most recently shipping AI governance and continuous control validation platforms to Fortune 500 customers at RelyanceAI. He was previously CTO of Interfold, a VC-backed fintech startup he built from zero to one.
Gaurav Kumar Sinha
Judge
Gaurav Kumar Sinha is a Senior Principal, Architecture at LTIMindtree and a former Senior Delivery Consultant at AWS Professional Services, with 15+ years architecting enterprise AI/ML and cloud platforms for Fortune 500 companies. A speaker at AWS re:Invent 2025 and author of 35+ publications, he founded SubstrAI, an open-source GenAI infrastructure ecosystem spanning AI-safety guardrails, LLM orchestration, and agent deployment.
San Krish
Judge
Sanjay Krishnegowda is a Data/AI engineer and the creator of agentic-guard, an open-source static analyzer that detects confused-deputy and prompt-injection risks in LLM agent code by modeling the LLM as an adversarially-controlled edge in the taint graph.
Syam Dondapati
Judge
I am an AVP Technical Developer at AIG specializing in database architecture for regulatory compliance across the US, Canada, Brazil, and South Africa, focusing on translating enterprise technology governance into real-world impact.
Tzu Kit Chan
Judge and Mentor
Tzu Kit Chan is Chief of Staff at Atlas Computing and an AGI-preparedness advisor to Southeast Asian decision-makers, and previously founded Caltech AI Alignment and led Stanford AI Alignment.
Yogesh Thanvi
Judge
Yogesh Thanvi is a cloud security and DevSecOps engineer with over fourteen years of experience securing internet-scale distributed infrastructure, holding deployment-approval authority across a global platform of more than 240,000 servers. He is the author of peer-reviewed research published in IEEE on cloud security posture management, Kubernetes admission control, and AI risk, and a named expert reviewer of the ISACA IT Audit Framework (ITAF). He holds the CISA and CDPSE certifications and serves on ISACA's IT Audit and Assurance Advisory Group.
Ankit Arya
Judge
Ankit is Head of AI at Inscope, where he builds AI-native financial reporting systems and works on the practical safety challenges of deploying LLMs in regulated, high-accuracy domains, from prompt injection defenses to evaluation design.
Ksheeraj Sai Vepuri
Judge
Ksheeraj Vepuri is a Senior Research Engineer at Meta Superintelligence Labs, where he leads initiatives in AI safety, alignment, and evaluation for multimodal foundation models. His work spans post-training reinforcement learning, automated red teaming, multimodal safety classifiers, and large-scale evaluation systems that support the safe deployment of generative AI products used by billions of people worldwide.
Ashwin Krishnappa Kumar
Judge
My name is Ashwin and I am a Senior Manager (IT Applications) at Tesla (where I lead a team of 22 engineers) with over 9 years of experience. I have expertise in data engineering, analytics, and AI integration and through my role help organizations make informed decisions swiftly and efficiently. I have also architected scalable data systems and developed user-centric applications that enhance operational performance through my past roles at Tesla (senior Staff Data Engineer, Staff Data Engineer, etc.).
Naga Sujitha Vummaneni
Judge
Naga Sujitha Vummaneni is a Senior Security Engineer at Ripple and Cornell MBA who has secured cloud and AI infrastructure at Google, Nike, and eBay, and publishes IEEE research on LLM and AI security. She authors the AI Security Weekly newsletter and serves as a technical program committee reviewer for IEEE conferences.
Rahul Nambiar
Judge
Building Propensity Labs to study AI model behaviour, specifically those leading to Loss of Control scenarios. Previously, led Data Privacy at Meta and built infrastructure at AWS.
Deepesh Khanna
Judge
Deepesh Khanna is a Technology Leader and an AI researcher with over 16 years of experience in enterprise architecture, artificial intelligence, cloud computing, and technology strategy. His work focuses on AI governance, Agentic AI, cloud-native platforms, compliance automation, and large-scale digital transformation. Deepesh has authored multiple research publications in AI and distributed systems, serves as a technology and innovation judge, and actively contributes to professional communities advancing responsible and scalable AI adoption.
Shantanu Bhatt
Judge
Shantanu Bhatt is a Senior Analyst in Product Security at Salesforce, where he leads enterprise security and compliance initiatives across AI and cloud systems, following prior roles auditing AI/ML and cloud infrastructure at Google. He is also the founder and CEO of iGrow Inc., where he has independently built and launched two AI-powered software platforms.
Surbhi Madan
Judge
Surbhi Madan is a Senior Software Engineer at Google working on the Google Maps AI rendering platforms and infrastructure (focused on AskMaps). She has worked at Google, based in NYC for 8+ years, and is passionate about creating scalable and sustainable platforms for feature teams. She also focuses on growing the next generation of tech talent by mentoring, teaching, and fostering a supportive and collaborative team environment. Surbhi is a graduate of Brown University and is heavily involved in Google's intern hiring program and has mentored several interns in the past.
Vivek Kumar
Judge
Vivek Kumar is an AI Governance Architect and creator of the PAARA framework, a connector-layer methodology for enterprise GenAI governance and AI risk assurance. His work focuses on AI governance, privacy, cybersecurity, agentic AI risk, retrieval-boundary governance, and enterprise AI connector security. He holds AIGP, CIPP/US, CIPP/E, CIPM, CISM, and FIP certifications and serves as IAPP KnowledgeNet Chapter Chair across Philadelphia, New Jersey, and New Delhi.
Juan Djuwadi
Judge
I'm a Product Manager on Google Search, focusing on growth across AI Mode and Search Apps. Previously was a gaming PM across Riot, EA, Niantic, etc.
Vasilii Kondyrev
Judge
Vasiliy is co-founder of Loyal, a confidential compute layer for agentic finance that recently raised $2.5M. He facilitates BlueDot's AGI Strategy course, speaks on AI security, and builds community across the AI safety ecosystem with a network of 300+ researchers, founders, and educators.
Pavel Sikachev
Judge
Pavel Sikachev is a product leader with 10+ years building AI-driven products - recently Chief Product Officer at Jume Platform (an AI-first enterprise company serving Fortune 500 clients including Danone and Unilever) and former Head of Kinship at Mars Petcare. He serves on award juries including the President Tech Award (Uzbekistan) and the CX World Awards (Moscow).
Joanna Wiaterek
Judge
Joanna co-directs the Centre for AI Security and Access, where she leads special projects on governance and financing mechanisms to bridge AI safety and global diffusion. Her work spans AI benefit-sharing to human-centered AI evaluations. Previously, she was a Fellow in the U.S. Congress.
Mark Gaffley
Judge
Mark Gaffley is an admitted attorney (South Africa) with over 13 years of legal & research experience gained through leading local and international organizations. He holds degrees in arts (history and sociology) and law, as well as a PhD in Jurisprudence, all from the University of Cape Town (UCT). His research focuses on the moral implications of artificial intelligence, particularly its effects on human autonomy and independent decision-making. Mark currently holds positions as Director: Legal & Operations at the Global Center on AI Governance; Legal Counsel at Simple.Capital; Honorary Senior Lecturer in the IF Gene RA Group, Department of Medicine, Faculty of Health Sciences, UCT; and Visiting Research Fellow, Southern Centre for Inequality Studies, WITS.
Jesús M. Siqueiros
Judge
His research focuses on participatory modeling, sustainability, and AI. In 2024, he received the Google Academic Research Award for the project Community Weavers of Artificial Intelligence and Nature-based Solutions. He leads the Lab-DEMOSS project, focused on experimenting with methods for integrating AI into social participation.
Amanda Isbosseth Guzmán Aceves
Judge
AI, Data Governance, Public Policies and Emerging Regulations on AI applied to local governments.
Marta Kosmyna
Judge
Marta Kosmyna is a policy expert working on AI governance and international security. Her research background specializes in emerging technologies used in warfare and law enforcement, and civilian protection in conflict zones.
Osmani Redondo
Judge
Director of AI Safety Spain and founder of Women4AISafety Spain. She drives the training and community ecosystem for AI safety within the Spanish-speaking world, connecting talent, resources, and opportunities with the global ecosystem.
Fernando Castillo
Judge
Fernando Castillo is a socio-technical cybersecurity researcher from Mexico working at the intersection of digital security, human rights, democracy, and AI safety. He founded Threat Trackers, a civil-society organization advancing the democratization of cybersecurity for communities underserved by the digital transition.
Marcos Galván López
Judge
Researcher in neurosymbolic artificial intelligence, explainable machine learning, formal reasoning systems, and probabilistic reasoning.
Silvia Fernández Sabido
Judge
Silvia Fernández Sabido is an 'Investigadora por México' fellow affiliated with CentroGeo. She holds a PhD in Physics from Henri Poincaré University (France) and specializes in Natural Language Processing and Computer Science.
Ivete Sánchez Bravo
Judge
PhD Candidate in Administration with a focus on Technological Innovation. Recognized as one of the top 20 AI leaders in Mexico, and recipient of the WAI Awards North America, which spans the United States, Mexico, and Canada. Participated in the Summer School on Responsible AI and Human Rights at Mila.
Germán López-Ardila
Judge
Coordinated the RAM Colombia Report (https://www.unesco.org/es/articles/colombia-avanza-hacia-una-inteligencia-artificial-etica-con-la-presentacion-del-informe-ram-de-la) (UNESCO, 2025) on the country's capacity to govern AI, and facilitates the UNESCO course AI Literacy for Public Servants (https://www.unesco.org/es/articles/fortaleciendo-las-capacidades-publicas-en-inteligencia-artificial-en-america-latina-una-alianza).
Diego Ortiz Barbosa
Judge
Co-author of CHAI (https://arxiv.org/abs/2510.00181) (SaTML 2026), prompt injection via fake visual cues in the environment that hijacks multimodal agents in drones, cars, and robots.
Diego Gomez
Judge
Works on multimodal LLM safety at YouTube and is developing a mechanistic interpretability project on persona vectors at BlueDot Impact (https://bluedot.org).
Maria Paula Mujica
Judge
Leads UNDP's Artificial Intelligence Landscape Assessment (https://www.undp.org/digital/aila) (AILA) across 16+ Global South countries. Co-author of the Ethical Framework for AI in Colombia (https://dapre.presidencia.gov.co/TD/MARCO-ETICO-PARA-LA-INTELIGENCIA-ARTIFICIAL-EN-COLOMBIA-2021.pdf).
Rajanikant Vellaturi
Judge
Rajanikantarao Vellaturi is an enterprise AI and data systems architect with more than 20 years of experience designing and operationalizing large-scale data, analytics, and artificial intelligence platforms. He has led critical data and AI initiatives across organizations including Apple, Kaiser Permanente, Cloudera, and Snowflake, with expertise in enterprise AI systems, cloud data architecture, data engineering, and AI-driven business transformation.
Phani Harish Wajjala
Judge
Phani Harish Wajjala is a Principal Machine Learning Engineer at Roblox, where he leads the ML decisioning layer that classifies and moderates millions of user-generated 3D assets. His work spans content-moderation evaluation, multimodal/VLM pipelines, and model calibration at production scale, backed by five U.S. patents and a CVPR 2026 workshop publication in the area.
Linh Nguyen
Judge
Linh Nguyen is an independent AI researcher and a recognized Google Developer Expert (GDE) in AI/ML, currently serving as the Head of AI at Obello, SF. Her recent contributions to the field include a top 25% submission with the Apart Research sprint and a co-authored paper accepted at an ICML 2026 workshop. Additionally, she is an active academic author with significant publications in journals such as Knowledge-Based Systems and Information Fusion.
Ajay Devineni
Judge
Ajay Devineni is a Senior SRE/DevOps Engineer and AI-SRE researcher with 13+ years of experience in cloud-native financial infrastructure. He is an IEEE Senior Member, AWS Community Builder, and creator of agentsre (https://github.com/Ajay150313/agentsre) an open-source Python library for AI-driven site reliability engineering. His research includes two accepted IEEE papers on intelligent incident prediction and LLM-based regulatory compliance automation in financial DevOps environments.
Venkata Sangaraju
Judge
Venkata Sangaraju is an AI, data, and analytics architect specializing in enterprise-scale data platforms, business intelligence, and AI-driven systems. His expertise spans AI governance, data architecture, information security, and responsible AI adoption. He is an invited speaker at Google Cloud Next 2026 and specializes in applying AI and data technologies.
David Mazumdar
Judge
David Mazumdar is a technology leader with 19+ years of experience evaluating and implementing enterprise AI, automation, and digital transformation solutions across global organizations. He has led large-scale AI enterprise solutions at Uber, General Motors and US Bank. David holds executive credentials in AI and leadership from MIT, Wharton, and Harvard Business School, and he is passionate about advancing responsible, scalable AI adoption.
Jonathan Ng
Judge
Jonathan Ng is an ML researcher and research engineer working on compute verification. He has also worked as a Research Engineer at Apart Research and Cadenza Labs, bringing experience across machine learning, software engineering, and AI safety research.
Royston Monteiro
Judge
Royston Pramod Monteiro is an Engineering Leader at Meta/Facebook, driving the technical development and scaling of Facebook Stories, growing it from Zero to a Billion users. With a background engineering complex systems at Goldman Sachs, Oracle, and Morgan Stanley, his current work explores the practical application of frontier large language models in developing autonomous agents. He holds a Master's degree from NYU.
Suprita Shankar
Judge
Suprita is an ML engineer on Apple's Foundation Models team, designing experiments to understand how data composition affects model performance. Previously, she was a tech-lead manager at Snorkel AI and a Founding Engineer at an Ed-tech startup.
Anchit Jhingan
Judge
Anchit Jhingan is a Senior Data Scientist with over 6 years of experience in big tech, specializing in machine learning, AI systems, and analytics. He currently works at Amazon Prime Video in the content localization domain. His work focuses on building intelligent systems to solve real-world business problems, particularly in media and entertainment.
Pratham Patkar
Judge
Pratham Patkar is Director of Business Systems at Society for Science, where he leads enterprise data architecture, AI readiness strategy, and data governance across the organization's many initiatives, including STEM research competitions, science education outreach, and science news publishing. He has designed data governance frameworks addressing GDPR, CCPA, and COPPA compliance, and has published research on constituent-first data governance for mission-driven organizations. His work explores how nonprofits can adopt AI responsibly without compromising the trust and data protection obligations they hold toward vulnerable constituent populations.
Michelle Malonza
Judge
Michelle is a Research Associate at ILINA, where she pursues two strands of work: the governance of AI in Global South countries, and the governance of AI agents in general. She also serves as Head of Policy, leading efforts to integrate AI safety considerations into African governments' AI decision-making. Her research includes work on the role of Global South countries in safe AI development and an analysis of the risks of automation-first AI adoption in these regions. Previously, Michelle was an AI Futures Fellow and Visiting Researcher at the Centre for the Study of Existential Risk (CSER). She holds an undergraduate law degree from Strathmore University and a Master of Laws degree from Columbia Law School.
Registered Local Sites
Register A Location
Beside the remote and virtual participation, our amazing organizers also host local hackathon locations where you can meet up in-person and connect with others in your area.
The in-person events for the Apart Sprints are run by passionate individuals just like you! We organize the schedule, speakers, and starter templates, and you can focus on engaging your local research, student, and engineering community.
Our Other Sprints
-
Research
Digital Minds Research Sprint
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Sign Up
-
Research
Secret Loyalties Hackathon
This unique event brings together diverse perspectives to tackle crucial challenges in AI alignment, governance, and safety. Work alongside leading experts, develop innovative solutions, and help shape the future of responsible
Sign Up

Sign up to stay updated on the
latest news, research, and events

Sign up to stay updated on the
latest news, research, and events
Sign up to stay updated on the
latest news, research, and events
Sign up to stay updated on the
latest news, research, and events